Object-Oriented Programming
来源: BlogBus 原始链接: http://www.blogbus.com:80/blogbus/blog/archive.php?id=3858 存档链接: https://web.archive.org/web/20041130020347id_/http://www.blogbus.com:80/blogbus/blog/archive.php?id=3858
一切只是开始 2004/03/25 到 2004/04/30 Linux, 嵌入式系统, 串口通信, PALM OS, Bluetooth ... 是工作中正用到的
Java, software engineering, 以及其他的很多技术,是我感兴趣的 OOP vs. NOOP
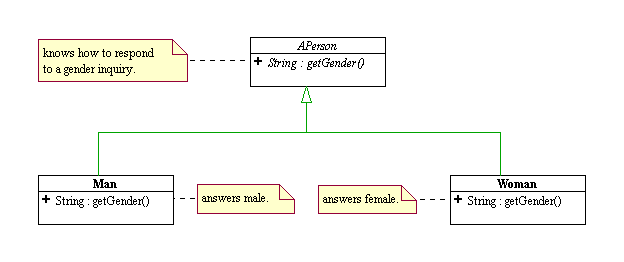
04/04/30 15:15 Object-Oriented Programming vs. Non Object-Oriented Programming Author: Dung "Zung" Nguyen Company: Rice University Description: Gordon Royle wrote: The following statement is a precis of a comment by a colleague. "Object Oriented Programming is just a structuring method for procedural programming, rather than a new paradigm." I disagreed quite strongly, but found it hard to convince him. What would your response be to such a statement, and how would you formulate an argument to support your point of view? I am not sure what Gordon's colleague means by "structuring method for procedural programming." Nevertheless, I will throw in my two cents on this (exciting) subject of Object-Oriented Programming (OOP) vs. Non Object-Oriented Programming (NOOP). I will respond to Gordon's colleague by presenting to him two concrete examples that I use in my class to illustrate to my students the differences between OOP and NOOP. My class is basically a CS2 course where the students are taught OOP using Java. My students were taught "program design" using Scheme in CS1 and are assumed to know something about functional programming, but nothing about OOP and Java. Example 1: I am dealing with people and need to know their genders. Write a program to model people and the fact that they know their genders and can respond to my inquiry about their genders. NOOP model : A person is either a man or a woman. I will model person with a class called Person. It has a boolean gender flag to record its gender. Whenever it is asked for its gender, it checks its internal flag and return "male" (or "female") accordingly. public class Person { private boolean _male; // true means male, false means female. public Person (boolean genderFlag) { _male = genderFlag; } public String getGender () { return _male? "male": "female"; } } I suspect the above model would correspond to what Gordon's colleague coins as "structuring method for procedural programming." But in my own opinion (IMOO), this model is not object-oriented at all. What is "wrong" with this model? Suppose I create a male person called bill: Person bill = new Person (true); // bill is a male person. And then I ask bill a thousand times for bill's gender in many statements like this one: if (bill.getGender ().equals ("male")) { //do something } Each time I ask bill for his gender, he has to check his internal flag before he can answer me. If the fact that bill is a male has a ready been made once at construction time, then why does bill have to keep checking his flag each time somebody ask him of his gender? I present this example to my class in the first lecture. I tell my students, "I ain't no Bill Clinton! I don't have to examine myself every time Hillary asks me if I am a man!" I think my students appreciate that. OOP model : A person knows intrinsically how to respond to a gender inquiry. A man is a person and knows specifically how to respond to the gender inquiry. A woman is a person and knows specifically how to respond to a gender inquiry. I model person as an abstract class called APerson with an abstract method for responding to the gender inquiry. I model a male person as class called Man and make it a concrete subclass of APerson. I model a female person as class called Woman and make it a concrete subclass of APerson. public abstract class APerson { public abstract String getGender(); } public class Man extends APerson { public String getGender() { return "male"; } } public class Woman extends APerson { public String getGender() { return "female"; } } http://www.owlnet.rice.edu/%7Ecomp212/99-fall/handouts/week1/person/person.png Now I will play God and create monica. APerson monica = new Woman (); // monica is a female person. if (monica.getGender ().equals ("female")) { // go smoke a cigar with bill } monica will answer directly my inquiry on her gender without hesitation, without any ifs, buts, nor conds, no matter how many times I ask her. The decision for monica to be a female has already been made at construction time. monica need not and should not check for anything else to respond to the gender inquiry. The key to this design is the representation of the abstract notion of a person as an abstract class with an appropriate abstract behavior . This abstraction of behaviors together with polymorphism allow us to hide away explicit state checking control structures in our code, reducing code complexity. Writing a program using classes does not automatically qualifies it as object-oriented as the above two designs illustrate. It is the object-oriented thinking (OOT) behind the design of a program that makes it object-oriented. The OOT that goes into the design of the class APerson and its concrete variants in the above can be summarized as follows. There is an abstract notion of a person that knows how to respond to a gender inquiry. A man is a person and knows how to respond to a gender inquiry in a very specific way. A woman is a person and knows how to respond to a gender inquiry in a very specific way. This way of thinking puts the emphasis on first identifying the abstract behaviors of a system instead of the data it must have. After the abstract behaviors are identified, we then encapsulate each concrete variant of the abstraction into a separate concrete subclass. When I talk about about encapsulation in OOT, I mean behavioral encapsulation, not data encapsulation. Data abstraction, IMOO, plays a secondary role in OOT. Data exist as attributes to help implement the concrete behaviors. The above formulation of an abstract person class and its concrete variants offer another subtle point: it allows me to add new concrete variants (e.g. eunuch?) to the model without changing any of the existing code. This is what code-reuse and extensibility is all about. Whereas if I formulate the problem as "a person is either a man or a woman," when I need to add a new "gender", I have to chase down all the switch statements in all of my code that are used for distinguishing the type of gender and make the appropriate modifications. That's another reason why I would characterize the first design as NOOP, and the thought process that goes into this design as NOOT (non object-oriented thinking). OOP is a translation of the (mental) model OOT creates into the form of a program . In theory, OOP can be done via a Turing machine, :-). But I prefer to use a convenient object-oriented language (OOL) to implement object-oriented designs (OOD). Employing modern visualization tools makes it much easier for me to get my points across to the students. For example, with BlueJ I can visually create bill and monica, point to each object, and ask for its gender. What I would like to see is "object-oriented hardware" that can execute object-oriented code in the most effective way. (Perhaps, my friend, Stephen Wong, would care to share some of his thoughts on this.) Now that my students have seen an illustration of OOP vs. NOOP, I send them home with the following problem and ask them to come back the next lecture with their best solutions using their most favorite programming language in order to compare notes with mine. Perhaps, Gordon can ask his " structuring method for procedural programming" colleague to do the same. I will present my solution in another post should y'all are curious to know. Example 2: The Best Little Pizza House in Texas is having a special on its pepperoni and cheese pizza. The special pizza comes in two shapes: rectangular (4" by 6") for $4.49 and circular (5" in diameter) for $4.69. The pizzas all have the same thickness. Which one is the better deal? Write a program to solve this problem. Why do we want to write a program to solve something as simple as this one anyway? Have a great day! Zung UML diagram for pizza example: http://www.owlnet.rice.edu/~comp212/99-fall/handouts/week1/Image1.gif file from the site: http://www.owlnet.rice.edu/%7Ecomp212/99-fall/handouts/week1/person/ Post by carol @ 15:15 关于 fork 和父子进程的理解
{kind=link}
{kind=link}
04/04/28 16:20 CU 上关于 fork 的一些讨论,讲得比较清楚,帮助我理解了多进程的概念 代码: #include <unistd.h> #include <sys/types.h> main () { pid_t pid; pid=fork(); if (pid < 0) printf("error in fork!"); else if (pid == 0) printf("i am the child process, my process id is %d\n",getpid()); else printf("i am the parent process, my process id is %d\n",getpid()); } 结果是 [root@localhost c]# ./a.out i am the child process, my process id is 4286 i am the parent process, my process id is 4285 我就想不到为什么两行都打印出来了,在我想来,不管pid是多少,都应该只有一行才对
naiza 写到: 这里的if和else不是以前理解的选择分支。fork后产生的子进程和父进程并行运行的 这种理解是不正确的。if 和 else 还是选择分支。 主要的原因是, fork() 函数调用一次,返回两次。 两次返回的区别是:子进程的返回值是0,父进程返回值为新子进程的进程ID。
但是只有一个pid=fork(); 呀,fork()返回的第二次值在什么时候赋给pid呢 pid这个变量是有两个的, 父进程一个, 子进程一个。
要搞清楚fork的执行过程,就必须先讲清楚操作系统中的 “进程(process)” 概念。一个进程,主要包含三个元素: o. 一个可以执行的程序; o. 和该进程相关联的全部数据(包括变量,内存空间,缓冲区等等); o. 程序的执行上下文(execution context)。 不妨简单理解为,一个进程表示的,就是一个可执行程序的一次执行过程中的一个状态。操作系统对进程的管理,典型的情况,是通过进程表完成的。进程表中的每一个表项,记录的是当前操作系统中一个进程的情况。对于单 CPU的情况而言,每一特定时刻只有一个进程占用 CPU,但是系统中可能同时存在多个活动的(等待执行或继续执行的)进程。 一个称为“程序计数器(program counter, pc)”的寄存器,指出当前占用 CPU的进程要执行的下一条指令的位置。 当分给某个进程的 CPU时间已经用完,操作系统将该进程相关的寄存器的值,保存到该进程在进程表中对应的表项里面;把将要接替这个进程占用 CPU的那个进程的上下文,从进程表中读出,并更新相应的寄存器(这个过程称为“上下文交换(process context switch)”,实际的上下文交换需要涉及到更多的数据,那和fork无关,不再多说,主要要记住程序寄存器pc指出程序当前已经执行到哪里,是进程上下文的重要内容,换出 CPU的进程要保存这个寄存器的值,换入CPU的进程,也要根据进程表中保存的本进程执行上下文信息,更新这个寄存器)。 好了,有这些概念打底,可以说fork了。当你的程序执行到下面的语句: pid=fork(); 操作系统创建一个新的进程(子进程),并且在进程表中相应为它建立一个新的表项。新进程和原有进程的可执行程序是同一个程序;上下文和数据,绝大部分就是原进程(父进程)的拷贝,但它们是两个相互独立的进程!此时程序寄存器pc,在父、子进程的上下文中都声称,这个进程目前执行到fork调用即将返回(此时子进程不占有CPU,子进程的pc不是真正保存在寄存器中,而是作为进程上下文保存在进程表中的对应表项内)。问题是怎么返回,在父子进程中就分道扬镳。 父进程继续执行,操作系统对fork的实现,使这个调用在父进程中返回刚刚创建的子进程的pid(一个正整数),所以下面的if语句中pid<0, pid==0的两个分支都不会执行。所以输出i am the parent process... 子进程在之后的某个时候得到调度,它的上下文被换入,占据 CPU,操作系统对fork的实现,使得子进程中fork调用返回0。所以在这个进程(注意这不是父进程了哦,虽然是同一个程序,但是这是同一个程序的另外一次执行,在操作系统中这次执行是由另外一个进程表示的,从执行的角度说和父进程相互独立)中pid=0。这个进程继续执行的过程中,if语句中pid<0不满足,但是pid==0是true。所以输出i am the child process... 我想你比较困惑的就是,为什么看上去程序中互斥的两个分支都被执行了。在一个程序的一次执行中,这当然是不可能的;但是你看到的两行输出是来自两个进程,这两个进程来自同一个程序的两次执行。 我的天,不知道说明白了没……
到底哪个进程执行在先,这个和操作系统的调度算法等等很多因素相关。我觉得理解上的困难,关键在于为什么会有两个输出,而不是谁先谁后。
fork之后,操作系统会复制一个与父进程完全相同的子进程,虽说是父子关系,但是在操作系统看来,他们更像兄弟关系,这2个进程共享代码空间,但是数据空间是互相独立的,子进程数据空间中的内容是父进程的完整拷贝,指令指针也完全相同,但只有一点不同,如果fork成功,子进程中fork的返回值是0,父进程中fork的返回值是子进程的进程号,如果fork不成功,父进程会返回错误。 可以这样想象,2个进程一直同时运行,而且步调一致,在fork之后,他们分别作不同的工作,也就是分岔了。这也是fork为什么叫fork的原因。 至于那一个最先运行,可能与操作系统有关,而且这个问题在实际应用中并不重要,如果需要父子进程协同,可以通过原语的办法解决。 Post by carol @ 16:20 Linux 下创建临时文件
04/04/26 22:27 Carol noted from << Beginning Linux Programming >> Chap 4 有时候程序需要一些文件形式的临时存储,来保留一些中间过程的操作。如果按照一般方式创建临时文件,可能会面临重名的问题,导致一些冲突。可以使用 tmpname() 函数来生成一个文件名,避免这种情况。 #include < stdio.h
char *tmpnam(char *s); tmpnam 返回一个不与已有文件重复的文件名。 如果临时文件创建以后马上使用,可以使用 tmpfile 函数来同时完成命名和打开。 #include < stdio.h
FILE *tmpfile(void); Tmpfile 函数返回文件流指针( FILE * ) , 指向生成的临时文件。文件可读可写(使用 fopen, w+ )而且在所有引用结束的时候自动删除。 例程: #include <stdio.h> int main() { char tmpname[L_tmpnam]; char *filename; FILE *tmpfp; filename = tmpnam(tmpname); printf("Temporary file name is: %s\n", filename); tmpfp = tmpfile(); if(tmpfp) printf("Opened a temporary file OK\n"); else perror("tmpfile"); exit(0); } When we compile and run this program, tmpnam.c, we can see the unique file name generated by tmpnam: $ ./tmpnam Temporary file name is: /tmp/filedm9aZK Opened a temporary file OK 更多关于创建临时文件的讨论 Temporary Files Often, programs will need to make use of temporary storage in the form of files. These might hold intermediate results of a computation, or might represent backup copies of files made before critical operations. For example, a database application could use a temporary file when deleting records. The file collects the database entries that need to be retained and then, at the end of the process, the temporary file becomes the new database and the original is deleted. This popular use of temporary files has a hidden disadvantage. You must take care to ensure that they choose a unique file name to use for the temporary file. If this doesn't happen, because UNIX is a multitasking system, another program could choose the same name and the two will interfere with each other. A unique file name can be generated by the tmpnam function: #include < stdio.h
char *tmpnam(char *s); The tmpnam function returns a valid file name that isn't the same as any existing file. If the string s isn't null, the file name will also be written to it. Further calls to tmpnam will overwrite the static storage used for return values, so it's essential to use a string parameter if tmpnam is to be called many times. The string is assumed to be at least L_tmpnam characters long. tmpnam can be called up to TMP_MAX times in a single program and it will generate a different file name each time. If the temporary file is to be used immediately, you can name it and open it at the same time using the tmpfile function. This is important, since another program could create a file with the same name as that returned by tmpnam. The tmpfile function avoids this problem altogether: #include < stdio.h
FILE *tmpfile(void); The tmpfile function returns a stream pointer that refers to a unique temporary file. The file is opened for reading and writing (via fopen with w+) and it will be automatically deleted when all references to the file are closed. tmpfile returns a null pointer and sets errno on error. Try It Out - tmpnam and tmpfile Let's see these two functions in action: #include <stdio.h> int main() { char tmpname[L_tmpnam]; char *filename; FILE *tmpfp; filename = tmpnam(tmpname); printf("Temporary file name is: %s\n", filename); tmpfp = tmpfile(); if(tmpfp) printf("Opened a temporary file OK\n"); else perror("tmpfile"); exit(0); } When we compile and run this program, tmpnam.c, we can see the unique file name generated by tmpnam: $ ./tmpnam Temporary file name is: /tmp/filedm9aZK Opened a temporary file OK How It Works The program calls tmpnam to generate a unique file name for a temporary file. If we wanted to use it, we would have to open it quickly to minimize the risk that another program would open a file with the same name. The tmpfile call creates and opens a temporary file at the same time, thus avoiding this risk. Older versions of UNIX have another way to generate temporary file names using functions mktemp and mkstemp . These are similar to tmpnam, except that you can specify a template for the temporary file name, which gives you a little more control over their location and name: #include < stdlib.h
char *mktemp(char *template); int mkstemp(char *template); The mktemp function creates a unique file name from the given template. The template argument must be a string with six trailing X characters. The mktemp function replaces these X characters with a unique combination of valid file name characters. It returns a pointer to the generated string, or a null pointer if it couldn't generate a unique name. The mkstemp function is similar to tmpfile in that it creates and opens a temporary file. The file name is generated in the same way as mktemp, but the returned result is an open, low-level, file descriptor. In general, you should use tmpnam and tmpfile rather than mktemp and mkstemp. Post by carol @ 22:27 对于 sizeof 的一些理解
04/04/26 20:13 初学者容易把 sizeof 和 strlen 搞糊涂,这是偶自己的一些理解: 偶用到 sizeof 和 strlen 的时候,通常是计算字符串数组的长度 看了上面的详细解释,发现两者的使用还是有区别的,从这个例子可以看得很清楚: char str[20]="0123456789"; int a=strlen(str); //a=10; >>>> strlen 计算字符串的长度,以结束符 0x00 为字符串结束。 int b=sizeof(str); //而b=20; >>>> sizeof 计算的则是分配的数组 str[20] 所占的内存空间的大小,不受里面存储的内容改变。 偶这样理解对吧 上面是对静态数组处理的结果,如果是对指针,结果就不一样了 char* ss = "0123456789"; sizeof(ss) 结果 4 ===》ss是指向字符串常量的字符指针,sizeof 获得的是一个指针的之所占的空间,应该是长整型的,所以是4 sizeof(*ss) 结果 1 ===》*ss是第一个字符 其实就是获得了字符串的第一位'0' 所占的内存空间,是char类型的,占了 1 位 strlen(ss)= 10 >>>> 如果要获得这个字符串的长度,则一定要使用 strlen 相关的讨论,可以到LU看, http://www.loveunix.net/index.php?showtopic=26953 附带两篇文章,写的更加详细。。。 Post by carol @ 20:13 Linux 无线网络技术
04/04/21 18:53 Linux 上的 WLAN、Bluetooth、GPRS、GSM 和 Infrared Data 一览 等级:中级 Sreekrishnan Venkateswaran ( s_krishna@in.ibm.com ) 专职软件工程师,IBM India 2004 年 4 月 当今,不考虑 Linux 和无线网络技术的话,就无法谈到计算机和网络。在这篇文章中,Sreekrishnan Venkateswaran 用 Linux 观点阐释了通过 WLAN、Bluetooth、GPRS、GSM 以及 IrDA 实现无线联网。他使用各种不同的无线设备和相应的内核层,以及用户空间工具来示范它们在 Linux 下如何工作。 无线技术,例如 WLAN (Wireless Local Area Network)、Bluetooth、GPRS (General Packet Radio Service)、GSM (Global System for Mobile communications) 以及 IrDa (Infrared Data),在不同的环境下提供服务。虽然 WLAN 支持比 Bluetooth 更高的速度和更长的传播距离,但是它也需要更多的费用并且耗电量更大。GPRS 虽然比 Bluetooth 和 WLAN 慢,但是可用于移动技术。尽管它们存在差异,或者是其他原因,但是具有多种无线功能的设备可以综合利用它们。例如,根据 GPS 模块的定位输入,设备可以透明地将网络连接从路上的 GPRS 切换到网吧中更便宜的 WLAN。移动电话可以通过 Bluetooth 与心律监视器通信,当病人心律超出某个极限时,就可以通过 GSM 向医生发送警报。 目前,无线技术已经以 PCMCIA、Compact Flash (CF) 卡的形式广泛应用,或者用于 USB 设备。大多数计算机系统,包括嵌入式设备,都有 PCMCIA、CF 或者 USB 接口,即使不含对无线技术的内置支持,也能够立刻使用这些技术。这篇文章分析了无线设备的一些示例,并且研究了设备驱动程序的 Linux 实现、总线技术以及各种协议。 首先,通过跟踪 WLAN 样卡的代码流,您将了解到 WLAN 设备是如何在 Linux 下工作的,然后还可以看到几个 Bluetooth 设备如何与 Linux Bluetooth 栈和其他内核层连接。接下来,您将了解到如何使 GPRS 和 GSM 设备在 Linux 下工作。文章最后分析了 Linux 上的 IrDa 支持并简要介绍了有关无线网络设备的性能问题。 注意: 本文涉及到的内核数据结构和文件名是当前 Linux 版本中所使用的。文件名相对于 Linux 内核源程序树的根。 Linux 802.11 WLAN WLAN 通信系统作为有线 LAN 以外的另一种选择一般用在同一座建筑内。WLAN 使用 ISM (Industrial、Scientific、Medical) 无线电广播频段通信。WLAN 的 802.11a 标准使用 5 GHz 频段,支持的最大速度为 54 Mbps,而 802.11b 和 802.11g 标准使用 2.4 GHz 频段,分别支持最大 11 Mbps 和 54 Mbps 的速度。 WLAN 类似于有线以太网,它们都是从同一地址池分配 MAC (Media Access Control) 地址,并且都是作为以太网设备出现在操作系统的网络设备层。例如,ARP(Address Resolution Protocol) 表是用 WLAN MAC 地址和以太网 MAC 地址填充的。 然而 WLAN 与有线以太网在链路层有很大的区别。例如,802.11 标准使用冲突避免(CSMA/CA)代替有线以太网的冲突检测(CSMA/CD)。而且,与以太网帧不同的是,WLAN 帧是被确认的。 由于 WLAN 工作站之间的模糊边界,WLAN 链路层拥有在传送前清除一个区域的协议。出于安全性考虑,WLAN 的 Wired Equivalent Privacy (WEP) 加密机制提供与有线网络相同的安全级别。WEP 将 40 比特或 104 比特密钥与随机的 24 比特初始向量组合用以加解密数据。WLAN 支持两种通信模式: Ad Hoc 模式 用于小群组工作站之间不必使用访问点的短时间内通信,而 Infrastructure 模式 的所有通信必须通过访问点。访问点周期性地广播一个服务集标识符(SSID),SSID 用于将一个 WLAN 网络与其他网络区别开来。 大多数可用的 WLAN 卡是基于 Intersil Prism 或 Lucent Hermes 芯片组的。Compaq、Nokia、Linksys 和 D-Link 卡使用 Prism 芯片组,而 Lucent Orinoco 卡和 Apple Airport 使用 Hermes 芯片组。 Linux WLAN 支持 Linux WLAN 支持由 WLAN API 实现和 WLAN 设备驱动程序组成。我将依次研究它们。 有两个 Linux 项目定义一般的 WLAN API,并且提供工具让用户空间应用程序配置参数和存取来自 WLAN 设备驱动程序的信息。Wireless Extensions 项目为不同的无线网卡提供公共的 Linux 用户空间接口。这个项目的工具包括 iwconfig 用以配置参数(比如 WLAN 驱动程序中的 WEP 关键字及 SSID)。linux-wlan 项目作为 Wireless Extensions 项目一部分,也支持一系列用于从用户空间与 WLAN 设备驱动程序交互的工具。与基于 Wireless Extensions 的工具不同,这些工具使用类似于 SNMP (Simple Network Management Protocol) MIB (Management Information Base) 的语法,该语法反映 IEEE 802.11 规范。(请参阅 参考资料 ,获得项目的更多信息。) 继续讨论设备驱动程序,支持流行的 WLAN 卡的 Linux 设备驱动程序包括: Orinoco WLAN 驱动程序: 是 Linux 内核源代码的一部分,支持基于 Hermes 的卡和基于 Intersil Prism 的卡。 orinoco_cs 模块提供了 PCMCIA 和 CF 卡所必需的 PCMCIA 卡服务支持。 linux-wlan 项目的 linux-wlan-ng 驱动程序: 支持多种基于 Prism 芯片组的卡。这个驱动程序支持 linux-wlan API 并部分支持 Wireless Extensions。 Host AP 设备驱动程序: 支持 Prism 芯片组的 AP 模式,可以使 WLAN 主机起访问点的作用。 Linux Symbol Spectrum 设备驱动程序: 支持 Symbol PCMCIA 卡。不同于 PCMCIA 卡,Symbol CF 卡缺乏板载固件,它依靠设备驱动程序来下载固件。该驱动程序的一个单独版本适用于 CF 卡。Intel 将 Symbol PCMCIA 卡重新打包为 Intel PRO/Wireless 卡,而 Socket 通信重新打包了 Symbol CF 卡。 Atmel USB WLAN 驱动程序: 利用 Atmel 芯片组支持许多 USB WLAN 设备。 请参阅 参考资料 ,获得这些设备的驱动程序信息。 Intersil Prism2 WLAN CF 卡 我将讨论 Intersil Prism2 802.11b WLAN CF 卡来展示它如何与 Linux PCMCIA、网络设备及协议层一起工作。 Linux PCMCIA/CF 层由 PCMCIA 主机控制器的设备驱动程序、不同卡的客户机驱动程序、用户模式程序、有助于热拔的后台进程和与以上各部分交互并为它们提供服务的内核卡服务中枢组成(请参阅 参考资料 )。PCMCIA 控制器将卡连接到系统总线,将卡内存映射到主机 I/O 和内存窗口,并将卡产生的中断路由到自由处理器中断线。CF 卡较小,但与 PCMCIA 兼容,并且经常应用于手持设备。PCMCIA/CF 卡拥有两个存储空间: 属性内存(attribute memory )和 公共内存(common memory) 。属性内存类似于 Card Information Structure (CIS),用来保存配置注册和描述符信息。Linux 卡服务核心与主机控制器设备驱动程序、卡设备驱动程序及用户模式 cardmgr 后台进程交互。它在一些事件(比如卡插入、卡移出以及低电量)发生时调用卡驱动程序的事件处理程序例程。尽管卡服务从卡的 CIS 向上传送信息到 cardmgr , 但是 cardmgr 将为分配内存窗口和中断级别而在用户空间(/etc/pcmcia/config.opts)中定义的资源分配策略向下传送到卡服务。查看 drivers/pcmcia/ds.c 可以了解与 cardmgr 交互的内核代码,查阅 /etc/pcmcia/config.opts 可以了解用户空间资源分配策略。 插入 Intersil WLAN CF 卡时,卡服务调用 orinoco_cs 模块的 PCMCIA 事件处理程序。卡服务解析卡属性内存中的 CIS 元组(tuples)并向上传送信息到 cardmgr ,这将从 /etc/pcmcia/config 文件(参阅清单 1)加载适当的设备驱动程序。由于卡的 CIS 中的 manfid 元组匹配 /etc/pcmcia/config 中的条目,所以 cardmgr 绑定带有 orinoco_cs 驱动程序的卡。清单 1 中的设备条目规定 orinoco_cs 驱动程序由三个内核模块组成: orinoco 、 orinoco_cs 和 hermes 。此外,由于设备属于 无线的(wireless) 一类,所以当启动和停止设备时, cardmgr 执行脚本 /etc/wireless/wireless。这个脚本使用 WLAN 工具和实用程序来配置设备驱动程序参数,例如 WEP 关键字和 SSID。它还可以启动 WLAN 上的网络协议,例如 DHCP(Dynamic Host Configuration Protocol,动态主机配置通讯协议)。清单 1 中的示例使用 Wireless Extensions 工具来执行设备配置。 注意: PCMCIA 配置文件的确切位置取决于所用的 Linux 分布。 清单 1. Intersil WLAN CF 卡的 PCMCIA 设备条目 card "Intersil PRISM2 11 Mbps Wireless Adapter" manfid 0x0156, 0x0002 bind "orinoco_cs" device "orinoco_cs" class "wireless" module "orinoco","orinoco_cs","hermes" 用 /etc/pcmcia/wireless 和 /etc/pcmcia/wireless.opts 脚本来配置 WEP 关键字和 SSID 这样的参数。 清单 2. 配置 WLAN 特定参数 iwconfig ethX essid <wlan_name> key AAAA-AAAA-AA [1] key BBBB-BBBB-BB [2] key CCCC-CCCC-CC [3] key DDDD-DDDD-DD [4] : Set 64-bit WEP Keys and ESSID in the driver iwconfig ethX : Display WLAN parameters iwpriv : Get nongeneric, driver-specific parameters iwlist : List Information and statistics from an interface iwspy : Read quality of link for a set of addresses /proc/net/wireless : Wireless Statistics from the device driver 在插入卡时, orinoco_cs 像传统的网络设备驱动程序一样,调用 register_netdev 来获得分配给 WLAN 接口的 ethX 网络接口名。它还会注册一个中断服务例程的地址以服务收发无线数据时产生的中断。中断处理程序是 orinoco 模块的一部分,并与 Linux 网络栈交互。Linux 网络栈使用主要的数据结构是 sk_buff 结构(定义在 include/linux/skbuff.h 中,请参阅 参考资料 ,该文件包括关于附加在它上的一个内存块的控制信息)。 sk_buffs 为所有网络层提供有效的缓冲器处理和流控制机制。网络设备驱动程序执行一个 dev_alloc_skb 和一个 skb_put ,以用 IP 数据填充一个 sk_buff ,然后通过调用 netif_rx 将这个 sk_buff 传送到 TCP/IP 栈。orinoco 中断服务例程用从 WLAN 接收的数据填充 sk_buffs ,并经由 netif_rx 将它传送到 IP 栈。 Linux TCP/IP 应用程序可以在前面谈到的内核模块为 Intersil WLAN CF 卡提供的网络接口上不加更改地运行。 Linux Bluetooth Bluetooth 是用于替换电缆的短程无线技术,支持 723 kbps(不对称)和 432 kbps(对称)的速度,可以传输数据和语音。Bluetooth 设备的传输范围大约 10 米(30 英尺)。(关于 Bluetooth 规范,请参阅 参考资料 。) BlueZ 是官方 Linux Bluetooth 栈,由主机控制接口(Host Control Interface ,HCI)层、Bluetooth 协议核心、逻辑链路控制和适配协议(Logical Link Control and Adaptation Protocol,L2CAP)、SCO 音频层、其他 Bluetooth 服务、用户空间后台进程以及配置工具组成(请参阅 参考资料 )。 Bluetooth 规范支持针对 Bluetooth HCI 数据分组的 UART(通用异步接收器/传送器)和 USB 传输机制。BlueZ 栈对这两个传输机制(drivers/Bluetooth/)都支持。BlueZ BNEP(Bluetooth 网络封装协议)实现了 Bluetooth 上的以太网仿真,这使 TCP/IP 可以直接运行于 Bluetooth 之上。BNEP 模块(net/bluetooth/bnep/)和用户模式 pand 后台进程实现了 Bluetooth 个人区域网(PAN)。BNEP 使用 register_netdev 将自己作为以太网设备注册到 Linux 网络层,并使用上面为 WLAN 驱动程序描述的 netif_rx 来填充 sk_buffs 并将其发送到协议栈。BlueZ RFCOMM(net/bluetooth/rfcomm/) 提供 Bluetooth 上的串行仿真,这使得串行端口应用程序(如 minicom)和协议(如点对点协议(PPP))不加更改地在 Bluetooth 上运行。RFCOMM 模块和用户模式 dund 后台进程实现了 Bluetooth 拨号网络。下面的列表给出了配置 Bluetooth 上的各种协议服务所必需的 BlueZ 模块、实用程序、后台进程以及配置文件。 下一步,考虑 Bluetooth CF 卡、Bluetooth USB 适配器、具有内置 CSR Bluetooth 芯片组的设备以及 Sony Bluetooth 耳机的示例,了解它们在 Linux 下是如何工作的。 Sharp Bluetooth CF 卡 Sharp Bluetooth CF 卡使用 UART 传输器来传送 HCI 数据分组。除了 serial_cs 是与 Linux PCMCIA 核心交互的卡服务驱动程序之外,Linux PCMCIA/CF 层与 Sharp 卡的其他操作系统的交互类似于针对 Intersil WLAN CF 卡所解释的交互。 serial_cs 驱动程序(将在下面的 “GSM 上的 Linux GPRS 和数据”一节中做进一步解释)模拟了 Sharp CF 卡上的串行端口。BlueZ hci_uart 链接驱动程序与 Bluetooth UART 通道交互并将模拟的串行端口连接到 BlueZ 栈。 下面的列表给出了当卡插入时必须加载的模块。其他的 Bluetooth CF 卡,例如 Pretec CompactBT 卡和 Socket Bluetooth 卡,具有 UART 接口,但是又有各自的卡服务驱动程序(分别是 drivers/bluetooth/dtl1_cs.c 和 drivers/bluetooth/btuart_cs.c)。在本文后面,您将发现更多关于 Bluetooth UART 传输器的信息。 /etc/pcmcia/config 中针对 Sharp Bluetooth CF 卡的条目: card "SHARP Bluetooth Card" version "SHARP", "Bluetooth Card" bind "serial_cs" 将要加载的必需的内核模块: insmod serial_cs insmod bluez insmod l2cap insmod hci_uart insmod bnep (for pand) insmod rfcomm (for dund) BlueZ 用户空间后台进程、实用程序以及配置文件: hciattach ttySx any [baud_rate] [flow] hciconfig -a :检查 HCI 接口。 hcitool -a hci0 scan 'flush :发现其他设备。 hcidump :HCI 嗅探器。 hcid :HCI 后台进程。 /etc/bluetooth/hcid.conf :hcid 所用的 HCI 后台进程配置文件,它指定了链接模式(主或从)、链接策略、询问和扫描模式,等等。 /etc/bluetooth/pinDB :BlueZ PIN 数据库。 hcidump :Service Discovery Protocol 后台进程。 pand :在 Bluetooth 上运行 TCP/IP(--listen 用于服务器,--connect <bluetooth_address> 用于客户机)。 /etc/bluetooth/pan/dev-up :pand 在激活 TCP/IP 时调用此脚本。此脚本能够包含一个类似于 ifconfig bnep0 <ip_address> 的命令,用以为 Bluetooth 接口配置 IP 地址。 hcidump :在 Bluetooth RFCOMM 上运行 PPP(--listen 用于服务器,--connect <bluetooth_address> 用于客户机)。 Belkin Bluetooth USB 适配器 Belkin Bluetooth USB 适配器拥有一个 Bluetooth CSR 芯片组,并使用 USB 传输器来传输 HCI 数据分组。因此,Linux USB 层、BlueZ USB 传输器驱动程序以及 BlueZ 协议栈是使设备工作的主要内核层。现在,您将了解到三层之间如何交互以使 Linux 网络应用程序在这个设备上运行。 Linux USB 子系统(请参阅 参考资料 )类似于 PCMCIA 子系统,它们都有与移动设备交互的主机控制器设备驱动程序,并且都包含一个向主机控制器和单个设备的设备驱动程序提供服务的核心层。USB 主机控制器遵循两个标准之一:UHCI(通用主机控制器接口)或 OHCI(开放式主机控制器接口)。由于具有 PCMCIA,单个 USB 设备的 Linux 设备驱动程序不依赖于主机控制器。经由 USB 设备传输的数据分为四种类型(或管道): Control Interrupt Bulk Isochronous 前两个通常用于小型消息而后两个则用于较大型的消息。 USB 设备插入时,主机控制器使用控制管道来枚举它并给它分配设备地址(1 到 127)。主机控制器设备驱动程序读取的设备描述符包含关于设备的信息,例如 class 、 subclass 和 protocol 。Linux 的 usbcore 内核模块支持 USB 主机控制器和 USB 设备。并包含 USB 设备驱动程序可以使用的函数和数据结构。USB 驱动程序利用 usbcore 及自己的 class/subclass/protocol 信息(请参阅 include/linux/usb.h 中的 struct usb_driver )注册了两个入口点:probe 和 disconnect。当相应的 USB 设备被附加时, usbcore 用枚举期间从设备配置描述符中读取的 class 信息来匹配已注册的 class 信息,并将设备与相应的驱动程序绑定。这个核心使用一种叫做 USB Request Block 或 URB(在 include/linux/usb.h 中定义)的数据结构,来异步地管理主机和设备之间的数据传输。设备驱动程序使用这些例程来请求各种类型的数据传输(control、interrupt、bulk 或 isochronous)。传送请求完成后,核心会使用以前注册的回调函数来通知驱动程序。 针对 Bluetooth USB 设备而言,HCI 命令使用 Control 管道传输,HCI 事件使用 Interrupt 管道,Asynchronous (ACL) 数据使用 Bulk 管道,而 Synchronous (SCO) 音频数据使用 Isochronous 管道。Bluetooth 规范为 Bluetooth USB 设备定义了 class/subclass/protocol 代码 0xE/0x01/0x01 。BlueZ USB 传输驱动程序(drivers/bluetooth/hci_usb.c)将该 class/subclass/protocol 信息注册到 Linux USB 核心。Belkin USB 适配器插入时,主机控制器设备驱动程序会枚举它。因为在枚举期间从适配器读取的设备描述符与 hci_usb 驱动程序注册到 USB 核心的信息相匹配,所以这个驱动程序可附加到 Belkin USB 设备。由 hci_usb 驱动程序从以上描述的各个端点读取的 HCI、ACL 和 SCO 数据被透明传送到 BlueZ 协议栈。一旦做完这些,通过使用以上描述的 BlueZ 服务和工具,Linux TCP/IP 应用程序就可以运行在 BlueZ BNEP 上,而串行应用程序则可以运行在 BlueZ RFCOMM 上。 具有内置 CSR Bluetooth 芯片组的母板 现在,关注一下具有内置 Bluetooth 芯片组的设备上的 Bluetooth 网络数据流。考虑一种拥有内置 CSR Bluetooth 芯片组的手持设备与使用 UART 接口的系统的连接。针对 UART 接口而言,在 Bluetooth 设备和系统之间传输 HCI 数据分组的可用协议有 BlueCore Serial Protocol (BCSP)、H4/UART 和 H3/RS232。而 H4 充当通过 UART 传输 Bluetooth 数据的标准方法。UART 是在规范中定义的来自 CSR 的专有 BCSP 协议,支持错误校验和重传。BCSP 用在基于 CSR BlueCore 芯片的非 USB 设备上,包括 PCMCIA 和 CF 卡。BlueZ 支持 BCSP 和 H4。 这个母板的 UART 通道使用的传统串行驱动程序可以从 BlueZ UART 传输驱动程序上收发数据。如果使用 BSCP 协议将 CSR 芯片设计为封装 HCI 数据分组,您必须使用 hciattach ( hciattach ttySx bcsp ) 通知 BlueZ 链接驱动程序,在这里 x 是连接到 CSR 芯片组的 UART 通道号。现在 hci_uart 与 CSR 芯片交互并且传送 Bluetooth 数据往返于 BlueZ 栈。 Sony HBH-30 Bluetooth 耳机 前面的 Bluetooth 设备示例展示了网络数据流。现在,通过查看 Sony Ericsson Bluetooth 耳机来考虑 Bluetooth 音频 (SCO) 数据的传输。在耳机可以开始与 Linux 设备通信以前,它必须被 Linux 设备上的 Bluetooth 链路层检测出来。因此,您必须将耳机置于发现模式(通过按下耳机上的一个按钮)。另外,您需要通过 Linux 设备上的 BlueZ 配置耳机的 PIN。Linux Bluetooth 设备上使用 BlueZ SCO API 的应用程序现在可以发送音频数据到耳机上。音频数据应当是耳机 可以理解的格式(例如,Sony 耳机的 A-law PCM [Pulse Code Modulation] 格式)。有些公共主域实用程序可以将音频(甚至文本文件)转换为各种 PCM 格式。 Bluetooth 芯片组除拥有 HCI 传输接口以外还有 PCM 接口 PIN。例如,如果设备同时支持 GSM 和 Bluetooth,GSM 芯片组的 PCM 线路可以直接与 Bluetooth 芯片的 PCM 音频线路连接。然后,您可能不得不在 Linux 设备上配置 Bluetooth 芯片组,以通过 HCI 传输接口而不是 PCM 接口收发 SCO 音频数据分组。 GSM 上的 Linux GPRS 和数据 GPRS 是一个用于通过 GSM 传输数据的数据分组服务,是一种卓越的数字蜂窝标准。尽管 GSM 上的数据是线路交换的并且不管怎样都占用一个通道,但是 GPRS 上的数据是一直连接的(always-on)、分组交换(packet-switched)的数据流,用户根据使用付费。GSM 的传输速度一般是 9.6 kbps,而 GPRS 能够运行的速度为 56 kbps 到 170 kbps。 GPRS 和 GSM 芯片通常有一个到系统的 UART 接口。对于内置 GSM/GPRS 支持的母板(例如,一个带有连接到 UART 通道的 Siemen MC-45 模块的母板),传统的串行驱动程序就能驱动这个链接。考虑 PCMCIA/CF 的形成因素(例如一张可选 GPRS 卡), serial_cs (是用于访问 PCMCIA 串行设备的普通卡服务驱动程序)能够允许其他操作系统把此卡当作一个串行设备。第一个未使用的串行设备(/dev/ttySx)被分配给此卡,然后此卡就可以被当成串行设备访问。 serial_cs 也可以通过全球定位系统 (GPS) PCMCIA 和 CF 卡模拟串行端口。针对 USB GPRS 调制解调器而言,USB-to-serial 转换器一般 USB 端口转换为虚拟串行端口,因此系统其他部分就会将它看作串行设备。 GPRS 网络使用 GGSN(GPRS 网关支持节点) 连接到一个外部网络(例如 Internet)。GPRS 设备类似于拥有扩展 AT 命令集的调制解调器,在进入数据模式之前必须使用 AT 命令定义一个上下文。上下文字符串看起来类似于清单 3 中给出的示例。 清单 3. 上下文字符串 'AT+CGDCONT=1,"IP","internet.voicestream.com","0.0.0.0",0,0' 在这个示例中, 1 代表上下文编号, IP 是数据分组类型, internet.voicestream.com 是接入点名称(APN) 字符串, 0.0.0.0 意味着服务提供者选择 IP 地址,其他参数与数据和报头压缩有关。APN 字符串取决于服务提供者。一般不需要用户名和口令。 PPP 允许网络协议(比如 TCP/IP)在串行链路上运行。在无线网络的上下文中,PPP 可以使 TCP/IP 运行于 GPRS 上,数据通过 GSM、Bluetooth RFCOMM 以及 IrDa COMM 进行传输。清单 4 给出了一种调用 PPP 后台进程 pppd 的公共语法。 清单 4. 调用 PPP 后台进程 pppd 的公共语法 pppd ttySx call connection-script 在这个示例中, ttySx 是物理或虚拟的串行设备(PPP 运行其上), connection-script 是 /etc/ppp/peers/ 目录中的一个文件,这个目录包含在 pppd 和服务提供者之间交换的用于建立链接的 AT 命令序列。建立链接并完成身份验证以后,PPP 将启动网络控制协议(Network Control Protocol,NCP)。IPCP (Internet Protocol Control Protocol,Internet 协议控制协议) 是用于运行 IP 的 NCP。一旦 IPCP 成功通过 IP 地址,PPP 就开始与 TCP/IP 栈交互。 清单 5 给出了用于连接到 GPRS 服务提供者的 PPP 链接脚本示例,而清单 6 给出的是用于到 GSM 服务提供者的数据连接的连接脚本示例。 清单 5. 针对 GPRS 的 pppd 链接脚本示例(/etc/ppp/peer/gprs-script) 115200 connect "/usr/sbin/chat -s -v "" AT+CGDCONT=1,"IP", "internet2.voicestream.com","0.0.0.0",0,0 OK AT+CGDATA="PPP",1" crtscts noipdefault modem usepeerdns defaultroute connect-delay 5000 从操作系统的角度出发,GSM 上的数据类似于通过拨号调试解调器连接收发的数据。互联网服务提供商(ISP)的电话号码是使用 GSM 拨入的,并且会建立一个拨号连接。利用用户名和口令进行身份验证。 一旦 PPP 建立了与服务提供者的 IP 连接,TCP 应用程序例如 Web 浏览器就可以不加更改地在 GSM/GPRS 设备上运行。 gsmlib 项目为通过 GSM 发送语音和 SMS(Short Messaging Service,短信服务)提供了实用程序(请参阅 参考资料 了解更多关于 gsmlib 的信息)。它包括用于存取 Subscriber Identity Module (SIM)卡中的电话簿、收发 SMS 消息等功能的实用程序。 清单 6. 用于通过 GSM 传输数据的 pppd 连接脚本示例(/etc/ppp/peer/gsm-script) 115200 connect '/usr/sbin/chat -s -v ABORT "NO CARRIER" ABORT "NO DIALTONE" ABORT "BUSY" "" AT OK ATDT<phone_number> CONNECT' crtscts noipdefault modem user "linux" usepeerdns defaultroute connect-delay 5000 Linux Infrared Data Infrared Data (IrDa) 是一种用红外线无线传输数据的规范。主要用于连接膝上电脑或者将录像机或照相机这样的设备连接到计算机系统。 IrDa 的速度从 Serial Infrared (SIR) 的 115 kbps 到 Very Fast Infrared (VFIR) 的 16 Mbps。大多数处于 SIR 模式的 IrDa 芯片是 UART 16650 兼容的(16650 是一种公共 PC UART),因此传统 Linux 串口驱动程序可以充当链路级别的驱动程序。IrDa 行的规范实现 ―― IrTTY (drivers/net/irda/irtty.c),使串行驱动程序驱动 SIR。IrPORT 驱动程序(drivers/net/irda/irport.c)代替了 IrTTY 和串行驱动程序,并提供更好的设备控制。与串行驱动器不兼容的 IrDa 芯片有自己的设备驱动程序。例如,NSC PC87108 芯片组就使用自己的驱动程序(nsc-ircc.c)。与上面讨论到的用于 USB Bluetooth 设备的 hci-usb 驱动程序类似,irda-usb.c 设备驱动程序支持 USB IrDa FIR 软件狗。 IrLAP 是负责 IrDa 设备发现、重传以及流控制的链路存取协议层。IrLMP 链路管理层和 Tiny 传输协议层(TinyTP)驻留于 IrLAP 之上。而它们之上是 IrCOMM 和 IrLAN 层。IrCOMM(在 net/irda/ircomm/ 中实现)提供串行模拟,使运行于串行端口(比如终端仿真器)上的应用程序不加更改地在 IrDa 栈上运行。IrLAN(在 net/irda/irlan/ 中实现)提供使 TCP/IP 直接运行于 IrDa 栈之上的虚拟网络接口。IrLAN 代码使用 register_netdev 将太网设备注册到 Linux 网络层,使用 netif_rx 向 Linux IP 栈发送数据(与对 WLAN 驱动程序和 Bluetooth BNEP的解释类似)。IrCOMM 与 Bluetooth RFCOMM 相似,而 IrLAN 则类似于 Bluetooth BNEP。 IrOBEX 是建立在 TinyTP 之上的一个简单协议,它允许传输二进制数据。IrOBEX 的扩展定义了不同数据对象的传输。 为了在 Linux 上应用 IrDa 协议,必须安装 IrDa 实用程序(如 irattach),它是作为 Linux IrDa 项目的一部分开发的。 性能问题 网络性能取决于特定载体网络的特征。例如,GPRS 的带宽取决于使用的代码模式,而 Bluetooth 的性能受 L2CAP 层的网段的影响。对于 WLAN 工作站与接入点之间的通信,帧确认会降低带宽, 使用同一接入点的其他工作站的数量也会带来同样影响。 无线网络的特征(比如低且波动的带宽和高延迟)会歪曲 TCP 度量和传输策略。尽管无线网络中的大多数损耗来自信号衰退、干扰以及连接中断等因素,但是 TCP 假定这些损耗与拥塞有关, 因此它摒弃了降低网络流量的算法。有多种项目用来调整 TCP 和 Web 浏览器的行为以适应无线网络。 结束语 在本文中,您浏览了是针对包括 WLAN、Bluetooth、GPRS、GSM 和 IrDA 在内的流行的无线技术的 Linux 设备驱动程序和网络协议层。还通过跟踪相应的代码路径和讨论相关的用户空间工具,了解到不同的无线设备如何在 Linux 中工作。 现在,有了对 Linux 上提供的对各种无线技术、网络技术以及总线技术的核心支持的理解,您可以修补多种具有不同形成因素的无线设备,开发启用不被支持的设备所需的 Linux 内核代码。 参考资料 阅读 Linux Wireless Extensions 项目页面 。 找到更多关于 linux-wlan 项目的信息。 了解更多关于 Linux Orinoco WLAN 驱动程序的信息,请到“ MPL/GPL drivers for the Wavelan IEEE/Orinoco and others ”。 了解更多关于 Intersil WLAN 卡的 Host AP 驱动程序的信息,请阅读“ Host AP driver for Intersil Prism2/2.5/3 ”。 这个网页包含 Spectrum-based WLAN 卡 (Socket、Intel Wireless/PRO 以及其他)的 Linux 设备驱动程序。 基于Atmel 的 USB WLAN 设备 的 Linux 驱动程序。 请阅读 Linux PCMCIA Programmer's Guide 。 Alan Cox 的“ Network Buffers ”提供了很好的关于 Linux 网络缓冲器(sk_buffs)管理的信息。 Bluetooth Web 站点提供关于 Bluetooth 规范的信息。 您说您喜欢在 Linux 下工作吗?该 Linux 的无线连接 教程会教给您如何在 Linux 下配置无线网卡( developerWorks ,2003 年)。 Linux BlueZ 主页提供了 BlueZ 的最新信息。 请阅读 Detlef Fliegl 的“ Programming Guide for Linux USB Device Drivers ”(2000 年)。 “ 在 Linux 上构建无线接入点 ”( developerWorks ,2003 年)这篇文章介绍了用 Linux 构建一个无线网桥所涉及到的内容,包括软件和硬件方面的考虑。 查看 Joshua Drake 和 Corwin Light Williams 的“ Linux PPP How-to ”(Linux Online! 2000 年)。 在 “ Open source wireless tools emerge ”( developerWorks ,2003 年)一文中,了解开放源代码工具正在兴起。 gsmlib 的主页提供了在 GSM 上工作的一组库和应用程序。 请参阅 Tips and Tricks ( developerWorks ,2002 年)这篇文章,学习如何管理可移动配置文件。 有关在 Linux 上使用红外通信的更多信息,请在 Linux IrDa 上查找。 关于作者 Sreekrishnan Venkateswaran 拥有印度坎普尔市印度科技学院的计算机科学硕士学位。他从 1996 年 2 月开始为 IBM India 工作。 他的兴趣包括设计设备驱动程序和网络协议。可以通过 s_krishna@in.ibm.com 与 Sreekrishnan 联系。 Post by carol @ 18:53 用prc-tool构造PALM的静态库
04/04/20 12:24 就这么几句命令行,累得我个半死,请 google 全球搜了一遍,可是codewarrior的还没搞定,选项乱七八糟的
- compile but no link *.c file m68k-palmos-gcc -g -O2 -c file.c -o file.o
- group *.o file into a static library,(named foo for example) m68k-palmos-ar rcs libfoo.a file.o file2.o file3.o ... libfoo.a 里的前缀 lib 和 后缀 .a 都是强制必须的
- using the static library: put the -lfoo at the end of the command m68k-palmos-gcc mainprog.o -o mainprog -L -lfoo Post by carol @ 12:24 用消息序列图描述实时系统与环境的交互作用[转贴]
04/04/19 08:43 用消息序列图描述实时系统与环境的交互作用 设计专栏, 嵌入式系统 上网时间:2003年09月27日 以图示方法来表示嵌入式系统内部各部件与环境的交互作用,是一种描述和理解嵌入式系统所常用的方法,本文从如何制作一个简洁、明了、直观、图示的标准化注释系统入手,说明如何确定嵌入实时系统的交互作用过程,重点介绍了基于消息序列图(Message Sequence Charts,MSCs)的注释系统的基础知识以及采用这种系统的好处。 描述实时系统的方法之一是列举其与环境的交互作用。消息序列图组是专门用于描述这一交互作用的简洁、严格和图示的直观注释。由于MSCs类似于UML,MSCs在电信行业中得到了普遍的应用,并且它在其它领域中的应用也日益广泛。 以图表形式来表示嵌入式系统内部各部件与环境的交互作用,是一种描述和理解嵌入式系统所常用的方法,这样的图表不仅在进行系统设计时很有用,而且在后期分析问题的过程中也发挥着作用。但是如何制作出一个有效的图表呢?工程师们需要的是一个简洁、明了、直观、图示意的标准化的注释系统,用以确定嵌入实时系统的交互过程。本文将介绍称为消息序列图的注释系统的基础知识以及采用这种系统的原因。 MSC是一种运算严格,表示方法简洁的图示技术。它在电信领域的应用十分普及,在实时安全和重要任务系统中的应用日益增加。序列图和在UML中的应用实例过程图都是直观的,并且语义上类似于MSC注释。 交互作用与交互作用假设 当以图形来描述一个嵌入式或实时系统时,我们要列举出系统环境与外部系统之间的交互作用,还要列举出一个过程与下一个过程之间的交互作用。要注意交互作用和交互作用假设(interaction scenario)之间的重要区别。 一个交互作用是指发生在参与实体当中的特定的事件序列。例如,温度计(外部系统)向系统控制器发送一条消息就是一个交互作用,消息也可能是一个交互作用。具体而言,在系统描述当中,还要描述系统的内部部件(子系统)之间的交互作用。对于复杂的系统,这种交互作用发生的形式多种多样。 一个交互作用假设,从另一方面来讲,详细描述了一个交互作用组,该交互作用组形成了一个交互作用的情节,并通常表示该情节中可能出现的事件序列。例如,压力计、控制器和阀之间存在各种交互作用,那么交互作用假设可能是指在压力太高的情况下三者之间使阀开启的相互作用过程。 每一个交互作用假设常被分为需要的(“晴天”)和不需要的(“雨天”)交互作用假设。理想情况下,将要实现的系统应当符合交互过程中所有需要的条件(“晴天”)而不出现一个不需要的条件(“雨天”)。 实体和事件 在一个消息序列图当中,实体是各种处理过程或子系统,而事件则表示通过实体发送和接收各种消息的行为。其它种类的事件,如与定时器相关的事件,也同样存在。在一个交互作用假设中,你可以想象实体作为一个执行者:它是一个事件的发送者或接受者。一个事件,从另一方面来讲,是指在两个执行者之间以发送消息的形式进行的通信。 处理过程(有时称之为例程)和消息的意义取决于系统。一个处理过程不一定代表计算机程序;它可指任何一个被激活的代理。消息不一定代表一个实际的数据消息,它可指在两个实体之间的另一种信息交换形式。例如,消息有一个命名,但却没有更深一层的结构或详细资料。 除非假定消息总是以发送顺序来接收,并且无任何丢失和毁损,消息序列图与消息传输的实际机制或渠道是无关的。在消息序列图注释中发送消息是不受阻碍的,意即发送者不必等到接受者接受到消息后才发送下一个消息。 应用实例 图1简单描述了阀、控制器和压力计这三个处理过程之间交互作用的消息序列图。每一个水平线表示该线所连接的实体上发生的事件,最顶部水平线表示的事件是从时间上看发生最早的事件,底部水平线表示的事件是最迟发生的事件。用于实体的临时事件顺序叫做局部顺序(local order)。局部顺序内的两个事件间的可视距离并非表示实际的距离。 在图1当中,阀和压力计两个实体各自将称为闭合状态(status_close)和高压状态(status_high_pressure)的消息发送到控制器。控制器然后向阀发送一个称为开启命令(cmd_open)的消息。这个消息序列图仅描写了一种交互作用假设,除此之外,尚有许多其它可能出现的情况,诸如阀在哪里开启、压力何时太低、控制器何时发出闭合阀的命令等等。 在消息序列图中,交互作用假设到底是指什么呢?看起来,消息序列图仅代表一个交互作用假设,或消息交换的一个序列。消息序列图,实际上表示几个消息序列,它们当中的每一个表示特定的行为。要明确地理解这一点,我们要确定在消息序列图的各个事件的先后顺序。 在图1中,有3个发送事件的消息和3个接受事件的消息,其命名如图2(a)所示。我们假定发送事件先于相应接受这一消息的事件,例如e1先于e2。此外,对于表示处理阀的沿垂直线分布的各个事件,e1先于e6发生。 在图2所示的优先顺序图表示各个事件的优先顺序。这个优先顺序图中的圆点代表事件,如果u先于v发生,箭头方向则从事件u指向事件v。事件v发生的前提条件是其前面的所有时间已经发生。消息序列图如果构成优良的话,其相应的优先顺序图就应该具有非循环指向(DAG)的特征;优先顺序图是连通的,意即无断点,也无回路或平行线。对任意两个圆点u和v,一定有一个从u到v或从v到u的路径。由于一个事件不可能先于它自己,一个自循环、从圆点指向其自身的箭头是不允许出现的。 根据优先顺序图,在消息序列图中的事件可被分为最小事件和最大事件两类。最小事件没有先于它发生的事件,最大事件也不可能有发生在其后的其它事件。例如,e1和e3是最小事件,e6是最大事件。如在它们之间不存在任何优先关系的话,两个事件是不可比较的。因此,事件e1和e3是不可比较的,事件e2和e3也如此。 确定了与消息序列图有关的优先顺序图,我们将消息序列图M中R的排序定义为M中各个事件中的一个序列,那么,M中每个事件在R中仅出现一次,并且对序列的任何一个事件也是如此;对于M而言,所有的先发生事件都遵循该优先顺序图。总而言之,消息序列图中,有几种可能的排序。一个消息序列图的完整意义包含其所有可能出现的排序。例如,图1中的消息序列图有如下3种可能的排序: 共区结构 图1中,控制器首先接收来自阀的状态关闭(status_close)消息,然后接收来自压力计的高压状态(status_high_pressure)消息。有时我们并不希望在这两个事件间出现这样的顺序。消息序列图注释允许通过应用一个叫做共区(coregion)的结构,从而避免对于一个处理过程而言,各个事件的某个子集出现任何特定的顺序。共区用表示处理过程的垂直线内虚线段来表示,这些虚线段内的事件是无序的。图3对图1进行了修改,它应用一个共区使事件e2和e4变得无序,它也表明了相关的优先顺序图。现在事件e2和e4是不可比较的,两者先于e5发生。 定时器结构 许多交互作用假设要用时序约束条件来限定消息流。通过应用三种专用事件:定时器设置、定时器复位和时间结束,你会很容易地在消息序列图注释中确定特定的交互作用假设。定时器设置通过将计时标记(hourglass)符号连接到一个单实体的时基上来表示;定时器复位通过将某个X连接到时基上来表示;时间结束用一根弯线将定时器的计时标记符号连接到实体时基来表示。 每一个定时器均有其特定的名字。对于每一个定时器而言,定时器复位和时间结束事件必定先于定时器设置事件。此外,时间结束事件是最后发生的事件。在图4中,在开始等待从阀和压力计实体发出消息前,控制器要启动定时器t1。控制器同时接收到来自阀和压力计的两个消息并将定时器复位,事件e7和e8表明定时器设置和定时器复位事件。图5显示了一个简明的消息序列图,图中控制器设定定时器t1(事件e7)并且在定时器t1(事件e9)时间结束前仅接受到来自阀的状态关闭(status_close)消息。 事件发生条件 条件是一种非正式描述机制,用以显示一个或一组实体达到的某个状态或情形。条件写为一个六边形框内的文本标签,可放置于某一实体或一组实体当中。如果条件C被置于实体E当中,那么除非条件得到满足,否则E不会进入到下一个事件。也就是说,条件C是实体中下一个事件发生的先决条件。如果将条件C被放置于一组实体E1,...,Ek之中,那么所有k个实体必须达到符合条件C的局部状态。只有在那个状态达到时,任何k实体才能在其相应的局部顺序中完成进一步处理。在这样的情况下,条件C可以被认为是完成进一步处理前确保实体E1,...,Ek达到相同状态的同步作用机制。 图6显示了图1中的消息序列图(稍作重新排序),并增加了一些条件,实体阀和压力计共享一个称为可用正确状态(correct_status_available)的条件。只有当这两个实体均达到满足该条件的某一状态时,它们才能按照其局部顺序进一步处理下去。该实体控制器必须达到某一状态,这个状态下实体控制器在接收状态信息前要满足准备接收状态(ready_to_receive_status)条件。这些条件的确切定义在此省略。 在线算子表达式 在线算子表达式(Inline operator expressions)是一种允许终端用户在消息序列图内确定补充控制流的机制,而且还可组合或合成多个消息序列图组。在线算子表达式当中,可以采用五种操作类型来确定控制流,分别是: *可选择组合 *平行组合 循环可选区域 *例外 从图解的意义来讲,在线算子表达式用一条由虚线水平分割的矩形来描述;算子关键字(operator keyword)标准在右上角。 图7利用具有可选算子的在线表达式合并了图4和图5中的消息序列图组。矩形内的虚线分割两个交替的路径,在一次执行过程中,消息序列图仅处理其中一条路径。 补充工具 消息序列图注释为描述嵌入式系统内部的交互作用提供了更为丰富的工具。消息的收发并不限于任何特定的实体,还包括外部环境。发向外部环境的消息,箭头止于消息序列图框上;从外部环境接收消息,箭尾止于消息序列图框上。 消息可包括附加信息。例如,通过阀处理所发送的开启状态(status_open)和闭合状态(status_close),消息可以合并成单个命名状态消息,上述两个状态的消息则以“status(open)”和“status(closed)”表示,其中的变量包含了消息值。 消息序列图的动作用矩形表示,矩形内包含了将要被执行的某项任务的文字描述。与某种“条件”类似,动作矩形被置于某一实体垂直线上。然而,与某种“条件”不同的是,一个动作是局部的;它只可相连于单个实体而不可跨越多个实体。将此动作作为特殊事件加以处理,我们可将它们包括进与消息序列图相关的优先顺序图当中。与各种“条件”类似,动作通常按非正式的描述加以处理。 消息序列图组中尚存在许多其它的工具,如消息门(gates for messages)。用户也可以一种标准化的、以事件为导向的文字句法对消息序列图加以描述,而不是以这里所给出的可视注释加以描述。 高层消息序列图 基本消息序列图注释描述了微小而特殊的基本交互作用,但复杂系统又怎样处理呢?一个复杂系统通常描述为各种子系统的分级组合,其交互作用描述为子交互作用的分级组合。 高层消息序列图(HMSC)增强了基本消息序列图注释以便描述子交互作用的组合。HMSC注释也支持自上而下的分级注释,其意义在于可在不同层的提取上确定各种交互作用,即通过基础消息序列图组描述从最高层开始到最底层的交互作用。 HMSC是一组由有方向的边相互连接起来的节点集合。每一个节点既是开始符号-,也是终止符号D,圆长方形包含某一个到另一个低层或高层消息序列图的参考,六边形包含一个条件,空心圆表示一个连接点或含有两个或更多平行的高层消息序列图组(HMSCs)的平行框。就组合的方面而言,实体不在HMSC中出现。连接点仅供方便布局之用,它们没有语义。HSMC中的各种条件具有整体性,其意义在于适用于所有实体并表示某一整体系统状态。 图8所示为控制器行为的HMSC。该行为由几个通过其它HMSC和MSC来说明的低层行为组成。通过这种方式,HMSC注释就可以自顶向下分层对行为进行分解。低层的HMSC可含有更深一层的HMSC或MSC。在此要强调的是,因HMSC是循环的,所以它不含终止符。我们已强调过:一个基本MSC总是有限的;但HMSC却不是这样,因为某个HMSC可能包含多个循环(表明是周期性的或循环的行为)。 复审和确认 项目要求的复审和确认,包含在那些应用消息序列图组确定的要求,是质理管理的重要组成部分。对于已用消息序列图确定的项目要求,还可用两种方法来复审和确认,一个是运行仿真,也称之为原型或模拟,可就特殊情形测试消息序列图组;另一个是确保消息序列图组满足特定的系统特征(原理)。 后者可采用工具自动检查HMSC,你可运用与临时逻辑有关的注释来表述特性并使用诸如模型检查和满意度来验证所给特性。此外,一些专用算法和工具可用来分析给定的HMSC,以自动检测若干意外的情况,如死锁、竞争条件和非局部选择。 购买指南 消息序列图为设计实时安全和重大任务系统的工程师提供有价值的服务。类似于在UML中的序列图和应用实例注释,消息序列图组有几点优于UML的性能。例如,消息序列图简化了在早期设计阶段的概念化系统要求。消息序列图将系统及其外部与该系统相互作用的所有实体描述为一个黑盒子,图表仅包含了一个有关系统与其外部环境间交互作用的简洁而非正式的描述。黑盒子和其外部实体作为消息序列图组中的单个实体,意即你无需知道或明确有关系统的内部结构或行为,当然我们己知的交互作用除外。这样的高层黑盒子交互作用导向的系统要求在UML中就说明得不够充分。 消息序列图组也可用作测试过程的规范(综合测试)。由于你可以运用消息序列图仿真、正式验证或完善规范,你可在实时嵌入系统的生命周期内广泛运用消息序列图组。此外,消息序列图注释也正因其特殊的应用价值而在几个领域广泛运用。例如,在计时消息序列图组中,上部和下部时限可用每一个消息加以规定,使其更适用于协议和实时系统。此外,由一套消息序列图组还可制作各种文件。 作者:Girish Keshav Palshikar Tata研究开发与设计中心 Email: girishp@pune.tcs.co.in 此文章源自《电子工程专辑》网站: http://www.eetchina.com/article_content.php3?article_id=8800319208 Post by carol @ 08:43 Record - 15th, April
04/04/15 22:14 串口传输程序今天交给他们测试了,后来发现,在只传一条数据的时候,PC接受端收不到 OVER 命令,只能再改了一下程序。明天在试试看。 今天终于搞清楚了怎么做 palm 的静态库,不过是在 prc-tool 的环境下的,codewarrior 还没有搞定。为了查那么一点点的资料,又用google把整个互联网转悠了一遍,收获颇多,提供了两篇教程到 tompda 上,居然还得了两个精华~~~ 嘿嘿!~ carol 出手,必属精品阿~ 有感于网上丰富细致的英文教程,不禁要为中文资料的匮乏汗颜了。―― 很少有人愿意做这类中文化的工作 ―― 新手练笔的翻译,过不了技术关;有了一定技术,能说点名堂出来的,又不屑于做这样的工作了。 另外,就国内高手的原创而言,似乎又不足够简单,认真的写了,新手却还是看不懂 ―― 高手的技术高得忘记自己初学时的理解过程了?这倒真的有可能是个表达能力的问题,中国的教育方式,不要说学不好英语,连国语都要成问题了 Post by carol @ 22:14 Record - 14th, April
04/04/14 23:10 今天从 uClinux 向 PC 传纪录的程序做好了 ―― 用了三天,多亏利用了原来现成的代码,要全让我重新做,不知道猴年马月呢。修改 bug 花掉好多时间啊,心疼。。。 明天又要重拾 PALM, 把代码做成 api ,静态库,给开发者调用。想到这个事情,郁闷就从心中升起, Ardio 和我讲了一大堆 静态库 的概念,可好像在 palm 上实现不完全和 vc 一样,只能求助论坛的朋友了。 今天带了一堆串口编程的资料回来,想在把 Linux Serial Programming how-to 翻译成中文简体版的基础上,补充另外几份资料的内容,增加整理,做一个 FAQ 。但现在觉得好像事情做起来不简单,我虽然对基本的串口编程比较熟悉了,但是涉及到很多底层的原理,就捉襟见肘了。英翻中应该难度不大,但是加上我自己的理解补充,就显得底气不足了。―― 甚至开始犹豫要不要花那么多时间来做这件事情。 Post by carol @ 23:10 WinCVS简明操作指南
04/04/14 12:44 WinCVS简明操作指南 作者:陈先波 邮件:turbochen@163.com 日期:2003-5-10 本文以WinCVS (ver 1.3.6.1 beta 6)为例来说明cvs的使用方法。
- 准备工作 1.1 术语 Update---从cvs服务器下载新版本文件。当本地文件比服务器上的还新时,update将失败。 Commit---将本地更新过的文件提交到cvs服务器。如果本地文件比服务器上的还旧,commit将失败。 Import Module---将本地模块建立到服务器上(即在服务器上新建一模块)。 Checkout Module---从服务器上取出一个模块。 1.2 准备目录 在使用CVS之前,要在你的电脑上建立一个空目录,主要用来存入cvs的系统信息,也可以用来存放从CVS服务器下载出来的文件。将这个目录命名为CVSHOME。 1.2 安装 请到 http://sourceforge.net/projects/cvsgui 下载WinCVS 1.3安装程序。下载完后执行setup.exe,按提示安装即可。 安装完后, 启动WinCvs,就可以看到主画面了, 主画面分为五个区域:
- 菜单---提供WinCvs的全部操作命令。
- 工具条---提供常用的操作命令。
- 树形菜单---目录浏览。
- 文件清单---文件视图。
- 控制台---命令执行的信息输出窗口,你也可以直接在里面输入cvs命令。 2.设置 2.1 设置常规选项 打开"Admin"菜单,点击"Preferences"子菜单。在"General"页中,设置与cvs服务器有关的选项: a.设置"Authentication"(认证方式),选择"pserver"。 b.设置"Path"(cvs服务器上的仓库根目录)。 c.设置"Host address"( cvs服务器名)。 d.设置"User name"(用户名),输入个人的cvs帐号,即Win2k Server的帐号。 e.设置"CVSROOT"参数,这是cvs专用的参数格式,如下所示: username@servername:path 其中username是帐号,servername是服务器名,path是cvs服务器上的仓库根路径。 2.2 设置全局选项 a."Checkout read-only"选项是设置当文件从服务器上check out出来后是否要设成唯读。 2.3 设置WinCvs选项 a."Default viewer used to open files"选项设置预设的文件查看器。 "Use on double click"选项设置当鼠标在文件上双击时,是否使用上面选项所设置的查看器打开。通常不要选择这项,让它用文件相关的程序打开。 b."External diff program"选项设置外挂的文件比较程序。 c."Home folder.(where cvs stores your passwords)"选项设置CVSHOME参数的目录。它是wincvs用来存放cvs登入密码的地方,将此目录设为先前建立的CVSHOME目录即可。 3.登入 点击"Admin"菜单,再点击"Login…"菜单, 之后出现一个password对话框, 输入密码,即可登入CVS服务器。登入后,wincvs将自动记住你的密码,下次使用wincvs时,可以不用人工登入。 下面是登入后,wincvs控制台输出的信息: 其中第一行是登入命令,第二行是登入信息,第三行是登入成功后返回的代码。通常看一个cvs的命令是否执行成功,可以看这个返回代码是否为0,否则此命令执行不成功。
- 新建模块 我们来看一下如何在cvs服务器上新建一个模块。 假设在本机的CVSHOME目录中有一个demo目录,此目录中有相关的源代码或是其它的文件。我们要将这个目录作为一个模块(Module),建立到cvs服务器上去。通常服务器上已建立好了一个CVSROOT目录,专门用来存放模块用的。 现在启动WinCvs程序,在窗口左边的树形目录中找到上面所示的目录位置。如果在这里找不到这个目录,可以点击"View"菜单,再点击"Browse Location",进入"Change"菜单,如下图, 这时出现对话框,找到demo目录所在的位置,点击"确定"即可。 这时,WinCvs的树形目录切换到了demo目录。在demo目录上点击鼠标右键,进入"Import Module"子菜单,这时出现下面的对话框: 选择demo目录,这时,wincvs自动识别出demo中所有文件的类型。所下图, 一般源代码等是TEXT格式的,而其它如图片,OFFICE文档等是二进制格式的。如果你发现WinCvs列出的格式与实际的格式不符,可以在相应的项目上双击来修改格式。 完成后按对话框上的"Continue"按钮,出现下面的对话框, 设置Module的名字为"demo",Vender tag和Release tag分别是制造和发行标记,可根据需要设置。在log message中设置一个日志信息,可以将来用作追踪用。 按"确定"按钮后,wincvs即开始执行import命令,并输出下图信息, 我们看到绿色是提交到服务器"demo"模块中的新文件。最后命令结果返回0,表示命令执行成功,已经在服务器上建立了一个demo模块,并且包含了所有的文件。 成功后你即可将本机的demo目录删除了。下面要来讲解如何从cvs服务器check out一个模块。
- Checkout模块 在WinCvs左边的树形目录上点击鼠标右键,进入"Checkout Module"菜单,出现下面的对话框, 输入你要checkout的模块的名字(注意大小写),即demo,再输入checkout下来后的存放目录,按"确定"按钮,这时,在WinCvs的控制台输出以下信息, 表示命令执行成功。这时,在WinCvs左边的树形目录中也多了一个demo的目录。相应的文件也在里面。
- update和commit文件 如果文件内容有改变,应即时的提交到服务器上。现在我们修改一个demo目录中的readme.txt文件,储存后,文件的图标即变成了红色,表示此文件被修改过,如下图, 这时,在此文件上点击鼠标右键,再点击"Commit selection…"菜单,出现下面的对话框, 输入log message后按确定即可。这时,控制台的输出信息如下, 表示命令执行成功。如果命令执行失败,可能是另外有人修改了这个文件并提交到了服务器。即服务器上的版本可能比你现有的文件还新,这时你有三种选择: a. 将服务器上的文件和本地的文件合并后再提交 先在文件上点击菜单命令"update…", 在弹出的对话框上什么都不要选,点击确定按钮,执行后,控制台输出下面的信息: 合并后的文件前面有一个M标记。 b. 用本地的文件将服务器上的文件覆盖 在文件上点击菜单命令"commit…",在出来的对话框上切换到Commit options页,选择Force commit,如下图, 按确定,命令执行后,控制台输出下面的信息, 其中可以看到文件版本从1.2变到了1.3. c. 用服务器上的文件将本地文件覆盖 在文件上点击菜单命令"update…",在出现的对话框中选择Get the clean copy,如下图, 按确定,命令执行后,控制台输出以下信息, 更新过的文件为绿色,前面标有U标记。同时,WinCvs会自动在此文件的当前目录备份更新前的文件,文件名前面会加上".#",后面会加上版本号。如上面的readme.txt文件会备份为".#readme.txt.1.4"。
- Add文件 如果在本机目录中新建了文件,必须用Add命令将它添加到cvs服务器。 假设我们在demo目录中新建了一个newfile.txt目录,如下图, 这个文件的图标显示为问号形式,并且在status栏也显示为"NonCvs file",表示这个文件还没有纳入cvs管理。 要将此文件加入到Cvs,请先选择它(如有多个文件,可以多选),点击"Modify"菜单中的"Add selection",如果是二进制文件,点击"Add binary"菜单,命令执行后,控制台的输出信息如下, 返回代码为0表示命令执行成功。执行后文件前的图标变为红色,cvs就认为这是修改过的文件,你还必须用前面提到的Commit方法将文件提交到cvs服务器。
- Remove文件 如果要将cvs中的文件删除,不能简单的将它从本机目录中删除,而必须借助Remove命令。不然的话,当你下次Checkout module时,在本机删除的文件又从服务器下载下来了。 假设我们现在要从cvs中删除newfile.txt文件。请先选择此文件(如有多个文件,可以多选),点击"Modify"菜单,再点击"Remove"菜单命令,这时控制台的输出信息如下, 这时此文件已被做了删除标记,文件前的图标变为红色。 如要真正的从cvs服务器上删除此文件,还必须再执行一次commit命令。 9.Remove空目录 在WinCvs中只提供了删除文件的功能,如要删除一个目录,必须先将这个目录中的文件用上面介绍的方法清空,然后再在WinCvs的树形菜单中选中你要删除的目录的上层目录,将光标移到控制台窗口中,输入以下命令: cvs update -P 完成后再执行一次update命令,即完成删除。
- cvs命令 除了用菜单命令外,你也可以在WinCvs的控制台中直接输入cvs的命令来执行。如要学习更多的cvs命令,可以在http://sourceforge.net/projects/cvsgui中找到相关的帮助。 更多文章,请访问: http://turbochen.go.nease.net/ Post by carol @ 12:44 C语言中可变参数的用法(转贴)
04/04/13 12:37
C语言中可变参数的用法
我们在C语言编程中会遇到一些参数个数可变的函数,例如 printf() 这个函数,它的定义是这样的:
int printf( const char* format, ...);
它除了有一个参数format固定以外,后面跟的参数的个数和类型是可变的,例如我们可以有以下不同的调用方法:
printf("%d",i);
printf("%s",s);
printf("the number is %d ,string is:%s", i, s);
究竟如何写可变参数的C函数以及这些可变参数的函数编译器是如何实现的呢?本文就这个问题进行一些探讨,希望能对大家有些帮助.会C++的网友知道这些问题在C++里不存在,因为C++具有多态性.但C++是C的一个超集,以下的技术也可以用于C++的程序中.限于本人的水平,文中如果有不当之处,请大家指正.
(一)写一个简单的可变参数的C函数
下面我们来探讨如何写一个简单的可变参数的C函数.写可变参数的
C函数要在程序中用到以下这些宏:
void va_start( va_list arg_ptr, prev_param );
type va_arg( va_list arg_ptr, type );
void va_end( va_list arg_ptr );
va在这里是variable-argument(可变参数)的意思.
这些宏定义在stdarg.h中,所以用到可变参数的程序应该包含这个头文件.下面我们写一个简单的可变参数的函数,改函数至少有一个整数参数,第二个参数也是整数,是可选的.函数只是打印这两个参数的值.
void simple_va_fun(int i, ...)
{
va_list arg_ptr;
int j=0;
va_start(arg_ptr, i);
j=va_arg(arg_ptr, int);
va_end(arg_ptr);
printf("%d %d\n", i, j);
return;
}
我们可以在我们的头文件中这样声明我们的函数:
extern void simple_va_fun(int i, ...);
我们在程序中可以这样调用:
simple_va_fun(100);
simple_va_fun(100,200);
从这个函数的实现可以看到,我们使用可变参数应该有以下
步骤
:
1)首先在函数里定义一个va_list型的变量,这里是arg_ptr,这个变量是指向参数的指针.
2)然后用va_start宏初始化变量arg_ptr,这个宏的第二个参数是第一个可变参数的前一个参数,是一个固定的参数.
3)然后用va_arg返回可变的参数,并赋值给整数j. va_arg的第二个参数是你要返回的参数的类型,这里是int型.
4)最后用va_end宏结束可变参数的获取.然后你就可以在函数里使用第二个参数了.如果函数有多个可变参数的,依次调用va_arg获取各个参数.
如果我们用下面三种方法调用的话,都是合法的,但结果却不一样:
1)simple_va_fun(100);
结果是:100 -123456789(会变的值)
2)simple_va_fun(100,200);
结果是:100 200
3)simple_va_fun(100,200,300);
结果是:100 200
我们看到第一种调用有错误,第二种调用正确,第三种调用尽管结果正确,但和我们函数最初的设计有冲突.下面一节我们探讨出现这些结果的原因和可变参数在编译器中是如何处理的.
(二)可变参数在编译器中的处理
我们知道va_start,va_arg,va_end是在stdarg.h中被定义成宏的,由于1)硬件平台的不同 2)编译器的不同,所以定义的宏也有所不同,下面以VC++中stdarg.h里x86平台的宏定义摘录如下(’\’号表示折行):
typedef char * va_list;
#define _INTSIZEOF(n)
((sizeof(n)+sizeof(int)-1)&~(sizeof(int) - 1) )
#define va_start(ap,v) ( ap = (va_list)&v + _INTSIZEOF(v) )
#define va_arg(ap,t)
( (t )((ap += _INTSIZEOF(t)) - _INTSIZEOF(t)) )
#define va_end(ap) ( ap = (va_list)0 )
定义_INTSIZEOF(n)主要是为了某些需要内存的对齐的系统.C语言的函数是从右向左压入堆栈的,图(1)是函数的参数在堆栈中的分布位置.我们看到va_list被定义成char,有一些平台或操作系统定义为void.再看va_start的定义,定义为&v+_INTSIZEOF(v),而&v是固定参数在堆栈的地址,所以我们运行va_start(ap, v)以后,ap指向第一个可变参数在堆栈的地址,如图:
高地址|-----------------------------|
| 函数返回地址 |
|---|
| ....... |
| ----------------------------- |
| 第n个参数(第一个可变参数) |
| ----------------------------- |
| 第n-1个参数(最后一个固定参数) |
| 低地址 |
| 图( 1 ) |
| 然后,我们用va_arg()取得类型t的可变参数值,以上例为int型为例,我们看一下va_arg取int型的返回值: |
| j= ( (int)((ap += _INTSIZEOF(int))-_INTSIZEOF(int)) ); |
| 首先ap+=sizeof(int),已经指向下一个参数的地址了.然后返回ap-sizeof(int)的int指针,这正是第一个可变参数在堆栈里的地址(图2).然后用取得这个地址的内容(参数值)赋给j. |
| 高地址 |
| 函数返回地址 |
| ----------------------------- |
| ....... |
| ----------------------------- |
| 第n个参数(第一个可变参数) |
| ----------------------------- |
| 第n-1个参数(最后一个固定参数) |
| 低地址 |
| 图( 2 ) |
| 最后要说的是va_end宏的意思,x86平台定义为ap=(char*)0;使ap不再指向堆栈,而是跟NULL一样.有些直接定义为((void*)0),这样编译器不会为va_end产生代码,例如gcc在linux的x86平台就是这样定义的. |
| 在这里大家要注意一个问题:由于参数的地址用于va_start宏,所以参数不能声明为寄存器变量或作为函数或数组类型. |
| 关于va_start, va_arg, va_end的描述就是这些了,我们要注意的是不同的操作系统和硬件平台的定义有些不同,但原理却是相似的. |
| (三)可变参数在编程中要注意的问题 |
| 因为va_start, va_arg, va_end等定义成宏,所以它显得很愚蠢,可变参数的类型和个数完全在该函数中由程序代码控制,它并不能智能地识别不同参数的个数和类型. |
| 有人会问:那么printf中不是实现了智能识别参数吗?那是因为函数printf是从固定参数format字符串来分析出参数的类型,再调用va_arg 的来获取可变参数的.也就是说,你想实现智能识别可变参数的话是要通过在自己的程序里作判断来实现的. |
| 另外有一个问题,因为编译器对可变参数的函数的原型检查不够严格,对编程查错不利.如果simple_va_fun()改为: |
| void simple_va_fun(int i, ...) |
| { |
| va_list arg_ptr; |
| char *s=NULL; |
| va_start(arg_ptr, i); |
| s=va_arg(arg_ptr, char*); |
| va_end(arg_ptr); |
| printf("%d %s\n", i, s); |
| return; |
| } |
| 可变参数为char*型,当我们忘记用两个参数来调用该函数时,就会出现core dump(Unix) 或者页面非法的错误(window平台).但也有可能不出错,但错误却是难以发现,不利于我们写出高质量的程序. |
| 以下提一下va系列宏的兼容性. |
| System V Unix把va_start定义为只有一个参数的宏: va_start(va_list arg_ptr); |
| 而ANSI C则定义为: va_start(va_list arg_ptr, prev_param); |
| 如果我们要用system V的定义,应该用vararg.h头文件中所定义的宏,ANSI C的宏跟system V的宏是不兼容的,我们一般都用ANSI C,所以用ANSI C的定义就够了,也便于程序的移植. |
| 小结: |
| 可变参数的函数原理其实很简单,而va系列是以宏定义来定义的,实现跟堆栈相关.我们写一个可变函数的C函数时,有利也有弊,所以在不必要的场合,我们无需用到可变参数.如果在C++里,我们应该利用C++的多态性来实现可变参数的功能,尽量避免用C语言的方式来实现. |
| 写这篇文章时,适逢感冒,多得有她的关怀,谨把这篇文章献给她... |
| 原作者: kevintz |
| junglesong 转载自 |
| www.chiangpa.com |
| Post by |
| carol |
| @ |
| 12:37 |
| 在堆上分配内存――摘自《编程修养》 |
04/04/12 22:04 在堆上分配内存 ――――――――― 可能许多人对内存分配上的“ 栈 stack ”和“ 堆 heap ”还不是很明白。包括一些科班出身的人也不明白这两个概念。我不想过多的说这两个东西。简单的来讲,stack上分配的内存系统自动释放,heap上分配的内存,系统不释放,哪怕程序退出,那一块内存还是在那里。 stack一般是静态分配内存,heap上一般是动态分配内存 。 由malloc系统函数分配的内存就是从堆上分配内存。从堆上分配的内存一定要自己释放。用free释放,不然就是术语――“ 内存泄露 ”(或是“内存漏洞”)―― Memory Leak。于是,系统的可分配内存会随malloc越来越少,直到系统崩溃。还是来看看“栈内存”和“堆内存”的差别吧。 栈内存分配 ――――― char* AllocStrFromStack() { char pstr[100]; return pstr; } 堆内存分配 ――――― char* AllocStrFromHeap(int len) { char pstr; if ( len <= 0 ) return NULL; return ( char ) malloc( len ); } 对于第一个函数,那块pstr的内存在函数返回时就被系统释放了。于是所返回的char*什么也没有。而对于第二个函数,是从堆上分配内存,所以哪怕是程序退出时,也不释放,所以第二个函数的返回的内存没有问题,可以被使用。但一定要调用free释放,不然就是Memory Leak! 在堆上分配内存很容易造成内存泄漏,这是C/C++的最大的“克星”,如果你的程序要稳定,那么就不要出现Memory Leak。所以,我还是要在这里千叮咛万嘱付,在使用malloc系统函数(包括calloc,realloc)时千万要小心。 记得有一个UNIX上的服务应用程序,大约有几百的C文件编译而成,运行测试良好,等使用时,每隔三个月系统就是down一次,搞得许多人焦头烂额,查不出问题所在。只好,每隔两个月人工手动重启系统一次。出现这种问题就是Memery Leak在做怪了,在C/C++中这种问题总是会发生,所以你一定要小心。一个Rational的检测工作――Purify,可以帮你测试你的程序有没有内存泄漏。 我保证,做过许多C/C++的工程的程序员,都会对malloc或是new有些感冒。当你什么时候在使用malloc和new时,有一种轻度的紧张和惶恐的感觉时,你就具备了这方面的修养了。 对于malloc和free的操作有以下规则:
- 配对使用,有一个malloc,就应该有一个free。(C++中对应为new和delete)
- 尽量在同一层上使用,不要像上面那种,malloc在函数中,而free在函数外。最好在同一调用层上使用这两个函数。
- malloc分配的内存一定要初始化。free后的指针一定要设置为NULL。 注:虽然现在的操作系统(如:UNIX和Win2k/NT)都有进程内存跟踪机制,也就是如果你有没有释放的内存,操作系统会帮你释放。但操作系统依然不会释放你程序中所有产生了Memory Leak的内存,所以,最好还是你自己来做这个工作。(有的时候不知不觉就出现Memory Leak了,而且在几百万行的代码中找无异于海底捞针,Rational有一个工具叫Purify,可能很好的帮你检查程序中的Memory Leak) Post by carol @ 22:04 轻而易举多接了个硬盘
04/04/12 21:02 之前一直想把 6。4 G的旧硬盘做成移动硬盘,最近发现只要把接光驱的几个接口插到旧硬盘,就可以正常访问了。今天试了下,超 easy ^_^ 。 于是整理很多觉得有价值的东西到旧硬盘,这才发现,机器上没有保留必要的东西还真多。当然也有一些,主要是以前自己写的东西,非常害怕会丢失,保留了好几份――我注定还是很怀旧的那种人。那些尘封的往事,其实已经再也不想看了。 越说越超出技术范围了,不谈也罢。 Post by carol @ 21:02 瞻前顾后
04/04/11 17:28 这两天体力透支,总是浑身酸痛,逢晚 11 点就睡意浓浓。碰上喜欢的闲聊对手,晚上的时间就飞阿飞的过去了,手都懒得动了。 关于中断登陆的 agetty 问题解决了,我就可以开始把旧的程序移植到新的终端上。原来的数据传输和程序下载,在 pc 段借助了 irda 的驱动,现在的程序,就不需要这个驱动了,而是由我们自己编写底层控制,对上层传输来说,区别不大。之所以要做这个看似重复的工作,使原来的 irda 传输不稳定。(我对新的直接控制方式的稳定性,还一点数都没有) 下周与 karl 约定的计划,是首先完成数据项从 uclinux 向 pc 的 Upload 。原来 karl 希望我把 upload 和 download 都在下周做掉。不过我觉得, upload 的程序,我之前做过,已经有了大的框架了,做起来应该比较顺利,同时避免很多新问题影响判断。 周五的时候,我已经把两端建立连接的部分做出来了,很顺利。我使用了一个之前已经写好的 pc 端程序,只改了很少的一点设置――效率大大提高! 下周的工作集中在 uclinux 端了,两个模块:从数据库中读取单条纪录(这要做一个新的 api 出来),把记录通过新的简单写已发出去(与 pc 的旧程序兼容即可)。如果效率高(一天 8 小时都在写)的话呢,两三天应该可以完成了。 555555~~~~~~~~~ 可怜我周二 Microsoft embedded system 的大会没的去了。 L 总结: 1. 流程图很管用。可以在编写代码之前,对整个程序的框架,结构做一个很清晰的分析。――看别人画的流程图效果还不够好,要按照自己的理解做一张出来,把输入,输出,需求都在脑海中形成一个框架,把工作任务模块化。虽然我要做的程序不算大,但还是被分解成两三个小模块。真正写代码的时候,集中精力各个击破就可以了。 2. 不要局限于简单的重复劳动。这次写代码的任务,应该说是我前段工作的重复和扩充。―― 人生最大的悲哀就是重复了。不过我是新手嘛 ~ 在重复中总结,也属于“温故而知新”。我至少可以做以下几件事情:修改不良代码,对于逻辑不清的,重复的,都可以通过在为原来的代码画流程图时候发现――《重构》;进一步巩固串口的控制知识,串口,包括终端,把其内部的工作搞得更明白一点;这次的工作,涉及到了对数据库的读写,顺标学习一下存储方面的知识。 Post by carol @ 17:28 Linux 下 C 编程从零开始
04/04/07 21:13 for www.loveunix.net by Carol see more discussion at: http://www.loveunix.net/index.php?showtopic=25570
这里向大家介绍一下在 Linux/UNIX 的机器上,进行 C/C++ 编程的一些入门级知识。 ・ 所需具备的背景知识 ・ 开发所需的基本环境 ・ 获得帮助的途径 ・ 通过一个实例了解基本步骤 Prerequisite 先决条件: 在 Linux 上编写 C 程序,至少要熟悉以下两方面的基础知识: 1 . C 语言的编程基础,至少要知道一些基本的语法,控制流程等编程常识。 对常用的标准 C 函数库有常识性的了解。 2 . 对 Linux/UNIX 的操作有常识性的了解,掌握常用的 shell 命令,如 ls, cat, cp, mkdir …etc. Environment 所需环境 : 1 . Linux/ Unix 的操作系统,也可以使用 windows 下的 cygwin 。 我们这里讨论的都是通过 shell 命令行进行操作的。那如果进入了图形界面的 Linux 怎么办呢?只要打开一个终端命令,就和命令行环境完全一样了(打开开始菜单可以找到终端命令)。 2 . 必备的开发工具: 1) 输入程序需要一个编辑器。常用的有 vi , emacs. 在命令行上输入 vi, emacs, … 就可进入编辑环境 关于 vi 关于 emacs 2) C 语言的编译器。常用的是 GNU 的 c 语言编译器 gcc( 编译 C 程序 ), g++( 编译 C ++ 程序 ) 。 关于 gcc / g++ 关于 makefile
用于简化编译过程 3) 调试程序的常用工具: gdb. 关于 gdb Get help 获得帮助: 关于 Linux 的文档是非常丰富的。最快捷,方便,全面的资料就在你的机器里,不要浪费。 在命令行上输入 shell 命令 man 或者 info : $man gcc >>>> 这个命令可以获得 GNU 的 C 语言编译器的文档。当然,他们是英文的。 关于 man 关于 info 网络上的资源也很多,多得以至于不知道什么才是自己最需要的。 关于如何获得有价值的信息 Basic steps 基本步骤: 1 . 输入源代码 2 . 编译,链接,运行 3 . 调试程序 我们从最基本的 hello world 程序开始,实际操作一下: 1 . 输入源代码 引用 $ emacs hello.c >>>> 进入 emacs 编辑器环境 #include <stdio.h> >>>> 如果你看不懂这个函数,就去好好的看 c 语言的书 int main() { printf(“Hello World.\n”); >>>> Emacs 环境下,按下 Tab 键,有自动缩进功能 exit(0); } 完成输入后,按住 CTRL 键,按下 x, 再按下 c , 最后松开 CTRL 。
程序保留并退出 emacs 环境。 2 . 编译,链接,运行 引用 $ gcc �Co hello hello.c $ ./hello >>>> ./ 指明了所执行程序的路径 Hello World. $ 一个 linux 平台上的 c 程序开发已经完成咯 3 . 调试 如果要使用 gdb 调试程序,那么在上一步编译的时候,记得加上 �Cg 选项 引用 $ gcc �Cg �Co hello hello.c $ gdb hello >>>> 进入 gdb 调试环境 嘻嘻,偶的原创哦。 ―― 边写边笑,边笑边写。想起一套很有名的系列书 “The Complete Idiot's Guide to ... ” 主要是最近很多新手来问问题,因为什么都不懂也问不出名堂来 高手莫笑,高手莫笑哈 更多的帮助指导信息稍候再补充 Post by carol @ 21:13 Record, 6th, April
04/04/06 21:52 嘻嘻,今天有点沾沾自喜哦
解决了一个莫名其妙的终端问题,偶们的工作可以继续进行下去了。
问题描述:
pc
上打开一终端通过
rs232
远程登陆
uClinux
的设备。可是在一切看似成功的情况下,我们发现
字母
’s’
无法在终端显示出来。这件事情非常痛苦,导致很多的
shell
命令,凡是包括
s
的,都无法正常执行。
Karl
甚至打算将所有的
s
都替换掉,这当然是下下之策。
昨天偶就做了很多排查工作,按照
karl
安排的步骤,确定问题到底出在哪里。
最后焦点集中在了
agetty 上,下午Karl给我指出了s显示不正常的地方,是经过了一段终端设置函数之后出现的。Karl试图删除设置函数,但是这样做导致了agetty执行失败。
还是多亏了我的 linux程序设计 这本宝书――简直就是偶linux变成的红宝书啦。很多事情就是踏破铁鞋无觅处的,最后找到得很轻松,我对着那一大堆 termios structure 的设置参数,一个个排查,哼哼,bug 浮出水面!
困了,未完待续 。。。
Post by
carol
@
21:52
Wikipedia - 维基百科
-
04/04/06 15:07
刀枪blue 的blog真是个好地方,每次去都能看到很多新奇的内容。
http://www.newseum.org/
就很棒
刚刚进入的维基百科也很不错,不,是很好 :)
英文版入口:
http://en.wikipedia.org/wiki/Main_Page
中文版入口:
http://zh.wikipedia.org/wiki/
明显的,中文版的内容还很少,需要很多国人的共同努力,不断补充。
Post by
carol
@
15:07
三大技术影响嵌入式应用
-
04/04/05 15:33
嵌入式系统是硬件与软件结合而构成的一个专门的计算装置,完成特定的功能或任务。它是一个大系统或重大电子设备中的一部分,工作在一个与外界发生交互并受到时间约束的环境中,在没有人干预的情况下进行实时控制。
目前,嵌入式技术在嵌入式应用中占主导地位,主要涉及三种技术:
嵌入式系统设计即软件与硬件相协同验证技术;
与基于
UML
的实时软件、实时操作系统应用开发等密切相关的嵌入式软件开发技术;
目前嵌入式应用亟待解决的嵌入式软件测试技术。
上述工具的灵活应用为嵌入式软件开发提供了完整的解决方案。但我国目前嵌入式应用的基础和水平还达不到这个要求,国内自主研发的产品还很少,甚至还是空白。因此,无论是对嵌入式软件开发人员,还是对国内厂商来说,任重道远。
1
系统设计:应用要灵活
嵌入式系统的主要工作模式是响应外部事件。它在软件控制下通过硬件来高速地获取数据,并进行处理,而后产生响应动作。而实时特征是嵌入式系统的主要特征,并根据截止时间的要求,可将实时分为硬实时和软实时。
硬件
/
软件协同技术
嵌入式系统的设计与当前的硬件所能提供的支持及软件技术的发展紧密相连。应用先进的硬件设计和开发技术,我们可以获得所需的性能。另外,软件的设计离不开硬件的支持,高性能、多功能的硬件允许我们在软件开发和设计上采用好的方法,应用好的语言,使用好的工具。
实时理论概念
嵌入式系统的软件设计与一般的软件设计有很大的不同,它涉及到更多的计算机理论和基于这些理论的算法以及有关的模型技术。实时设计在概念上除了通常的软件设计概念外,有限状态机、并发任务等概念对于实时嵌入式系统的设计相当重要。
实时设计表示
实时嵌入式应用的多样性,是指实时嵌入式应用的不同,所涉及到的问题也不同,所采用的设计方法和设计手段也不同,但从设计角度来决定实时设计中仍要涉及一些具体问题。
实时构件
通过构件组装软件这种方式,可以大大提高软件的开发效率,保证软件的质量。特别是对于实时嵌入式软件,涉及到大量的和时间相关的算法,如果将它们模块化或构件化,并按照特定的模式
/
定式和框架在软件开发中重用它们,其意义不言而喻。另外,基于构件进行软件开发,还有利于软件开发的自动化。
设计定式和框架
两者都是通过收集成功的软件开发策略来推动重用,其主要差别表现为框架的重点是在具体的设计、算法及应用特定编程语言进行实现的重用上,而定式的重点则是放在抽象设计和软件小型结构的重用上。显然,应用设计定式和框架技术,能够改进软件质量,缩短软件开发时间,也有利于软件开发的自动化。
2
软件开发:实时是关键
嵌入式应用软件典型的开发方式是“宿主机
/
目标机”方式,首先利用宿主机上丰富的资源、良好的开发环境开发和仿真调试目标机上的软件,然后通过串口、网络或其它接口将交叉编译生成的目标代码传输并装载到目标机上,并用交叉调试器在监控程序或实时操作系统的支持下进行运行调试。最后,目标机在特定的环境下运行。
实时编程及最小编程环境
运用软件设计方法进行实时嵌入式软件的设计,应用编程语言完成实时嵌入式软件的实现。而应用高级语言或实时编程语言开发实时嵌入式软件,最基本的要求是要有一个最小编程环境,如交叉编译、交叉调试器、宿主机和目标机间的通信工具、目标代码装载工具、目标机内驻监控程序或实时操作系统等。
实时操作系统
实时操作系统是指能进行实时处理的操作系统,它分为两类:一类是专为实时应用设计的专用操作系统,其核心是实时内核;另一类则是在通用操作系统的基础上增加实时功能,如实时
Linux
、实时
UNIX
等,其扩展部分是实时执行程序。
实时数据库
在实时数据库中,除了通常对逻辑要求一致以外,还有事务处理完成时间的约束及数据访问和更新时间的约束等。为了满足时间约束和结果可确定的基本需求,开发者不仅要对通常的调度方法和事物管理进行重新设计,而且还要提出在通常数据库系统中没有考虑到或者在实时系统中要增加的新概念,以及对应的新技术。
实时中间件
提高软件生产率和软件质量的需求激发了人们使用中间件的愿望。中间件位于应用和底层之间。它能够使系统设计人员从部件位置、编程语言、
OS
平台通信协议和互连以及硬件依赖中解放出来,从而大大地简化了软件的开发。
目前,分布式实时系统开发趋势是:编程采用可重用部件,对整个分布式应用部件采用远程方法调用,并在异构环境下尽量定义标准的软件底层基础,在系统中确保
QoS
的需求。
3
软件测试:把好开发关
软件测试在整个软件开发过程中处于非常重要的地位,其测试费用占项目总费用的
25%
以上,对于嵌入式软件则花费更大。嵌入式应用软件的测试同人们通常使用的传统的软件测试相比有较大的差别,除了要考虑和运用传统的测试技术外,还要考虑与时间和硬件密切相关的测试技术运用,如:对外部事件响应的测试问题。
软件分析技术
实时嵌入式系统最大的特点是具有一组动态属性,即中断处理和上下文切换、响应时间、数据传输率和吞吐量、资源分配和优先级处理、任务同步和任务通信等。所有这些性能属性可以很容易地说清楚,但要测试或验证它们(特别是时间确认)是很困难的。因此,对实时嵌入式系统进行分析需要建模和仿真,以及对数学工具的支持。
软件测试技术
测试技术,指的是软件测试的专门途径,以及提供能够更加有效地运用这些途径的特定技术。这些技术可分别用在软件开发过程中的不同阶段,如:开发方的内部测试、第三方的验证和确认测试和维护中的修改和升级测试等。
测试策略主要针对软件测试里的诸多问题而言。对于测试,首先要建立一个好且实用的测试文档标准和开发方及测试方的协作关系,然后明确测试需求和目的及测试过程,制订测试计划,最后进行测试的开发、实施、分析和报告。
软件调试技术
软件调试是在软件测试之后进行,用以定位和排除错误。对于嵌入式应用,无论是测试还是调试,有效的方法仍是借助硬件仿真的手段辅助软件来进行测试和调试。
仿真器一般是由硬件和软件构成。硬件提供低级的监控、控制和保护功能,而在仿真器里的软件提供状态和控制功能以及与宿主机的通信。人们通过调试器用户接口同仿真器的硬件和软件打交道来控制和监督微处理器的工作,从而定位或发现软件的错误。
实际上,仿真器既可用来发现软件错误,也可用来查找硬件错误。这就是仿真器和调试器的主要区别。
Post by
carol
@
15:33
用消息序列图描述实时系统与环境的交互作用
-
04/04/03 23:35
用消息序列图描述实时系统与环境的交互作用
设计专栏, 嵌入式系统
上网时间:2003年09月27日
以图示方法来表示嵌入式系统内部各部件与环境的交互作用,是一种描述和理解嵌入式系统所常用的方法,本文从如何制作一个简洁、明了、直观、图示的标准化注释系统入手,说明如何确定嵌入实时系统的交互作用过程,重点介绍了基于消息序列图(Message Sequence Charts,MSCs)的注释系统的基础知识以及采用这种系统的好处
。
描述实时系统的方法之一是列举其与环境的交互作用。消息序列图组是专门用于描述这一交互作用的简洁、严格和图示的直观注释。由于MSCs类似于UML,MSCs在电信行业中得到了普遍的应用,并且它在其它领域中的应用也日益广泛。
以图表形式来表示嵌入式系统内部各部件与环境的交互作用,是一种描述和理解嵌入式系统所常用的方法,这样的图表不仅在进行系统设计时很有用,而且在后期分析问题的过程中也发挥着作用。但是如何制作出一个有效的图表呢?工程师们需要的是一个简洁、明了、直观、图示意的标准化的注释系统,用以确定嵌入实时系统的交互过程。本文将介绍称为消息序列图的注释系统的基础知识以及采用这种系统的原因。
MSC是一种运算严格,表示方法简洁的图示技术。它在电信领域的应用十分普及,在实时安全和重要任务系统中的应用日益增加。序列图和在UML中的应用实例过程图都是直观的,并且语义上类似于MSC注释。
交互作用与交互作用假设
当以图形来描述一个嵌入式或实时系统时,我们要列举出系统环境与外部系统之间的交互作用,还要列举出一个过程与下一个过程之间的交互作用。要注意交互作用和交互作用假设(interaction scenario)之间的重要区别。
一个交互作用是指发生在参与实体当中的特定的事件序列。例如,温度计(外部系统)向系统控制器发送一条消息就是一个交互作用,消息也可能是一个交互作用。具体而言,在系统描述当中,还要描述系统的内部部件(子系统)之间的交互作用。对于复杂的系统,这种交互作用发生的形式多种多样。
一个交互作用假设,从另一方面来讲,详细描述了一个交互作用组,该交互作用组形成了一个交互作用的情节,并通常表示该情节中可能出现的事件序列。例如,压力计、控制器和阀之间存在各种交互作用,那么交互作用假设可能是指在压力太高的情况下三者之间使阀开启的相互作用过程。
每一个交互作用假设常被分为需要的(“晴天”)和不需要的(“雨天”)交互作用假设。理想情况下,将要实现的系统应当符合交互过程中所有需要的条件(“晴天”)而不出现一个不需要的条件(“雨天”)。
实体和事件
在一个消息序列图当中,实体是各种处理过程或子系统,而事件则表示通过实体发送和接收各种消息的行为。其它种类的事件,如与定时器相关的事件,也同样存在。在一个交互作用假设中,你可以想象实体作为一个执行者:它是一个事件的发送者或接受者。一个事件,从另一方面来讲,是指在两个执行者之间以发送消息的形式进行的通信。
处理过程(有时称之为例程)和消息的意义取决于系统。一个处理过程不一定代表计算机程序;它可指任何一个被激活的代理。消息不一定代表一个实际的数据消息,它可指在两个实体之间的另一种信息交换形式。例如,消息有一个命名,但却没有更深一层的结构或详细资料。
除非假定消息总是以发送顺序来接收,并且无任何丢失和毁损,消息序列图与消息传输的实际机制或渠道是无关的。在消息序列图注释中发送消息是不受阻碍的,意即发送者不必等到接受者接受到消息后才发送下一个消息。
应用实例
图1简单描述了阀、控制器和压力计这三个处理过程之间交互作用的消息序列图。每一个水平线表示该线所连接的实体上发生的事件,最顶部水平线表示的事件是从时间上看发生最早的事件,底部水平线表示的事件是最迟发生的事件。用于实体的临时事件顺序叫做局部顺序(local order)。局部顺序内的两个事件间的可视距离并非表示实际的距离。
在图1当中,阀和压力计两个实体各自将称为闭合状态(status_close)和高压状态(status_high_pressure)的消息发送到控制器。控制器然后向阀发送一个称为开启命令(cmd_open)的消息。这个消息序列图仅描写了一种交互作用假设,除此之外,尚有许多其它可能出现的情况,诸如阀在哪里开启、压力何时太低、控制器何时发出闭合阀的命令等等。
在消息序列图中,交互作用假设到底是指什么呢?看起来,消息序列图仅代表一个交互作用假设,或消息交换的一个序列。消息序列图,实际上表示几个消息序列,它们当中的每一个表示特定的行为。要明确地理解这一点,我们要确定在消息序列图的各个事件的先后顺序。
在图1中,有3个发送事件的消息和3个接受事件的消息,其命名如图2(a)所示。我们假定发送事件先于相应接受这一消息的事件,例如e1先于e2。此外,对于表示处理阀的沿垂直线分布的各个事件,e1先于e6发生。
在图2所示的优先顺序图表示各个事件的优先顺序。这个优先顺序图中的圆点代表事件,如果u先于v发生,箭头方向则从事件u指向事件v。事件v发生的前提条件是其前面的所有时间已经发生。消息序列图如果构成优良的话,其相应的优先顺序图就应该具有非循环指向(DAG)的特征;优先顺序图是连通的,意即无断点,也无回路或平行线。对任意两个圆点u和v,一定有一个从u到v或从v到u的路径。由于一个事件不可能先于它自己,一个自循环、从圆点指向其自身的箭头是不允许出现的。
根据优先顺序图,在消息序列图中的事件可被分为最小事件和最大事件两类。最小事件没有先于它发生的事件,最大事件也不可能有发生在其后的其它事件。例如,e1和e3是最小事件,e6是最大事件。如在它们之间不存在任何优先关系的话,两个事件是不可比较的。因此,事件e1和e3是不可比较的,事件e2和e3也如此。
确定了与消息序列图有关的优先顺序图,我们将消息序列图M中R的排序定义为M中各个事件中的一个序列,那么,M中每个事件在R中仅出现一次,并且对序列的任何一个事件也是如此;对于M而言,所有的先发生事件都遵循该优先顺序图。总而言之,消息序列图中,有几种可能的排序。一个消息序列图的完整意义包含其所有可能出现的排序。例如,图1中的消息序列图有如下3种可能的排序:
共区结构
图1中,控制器首先接收来自阀的状态关闭(status_close)消息,然后接收来自压力计的高压状态(status_high_pressure)消息。有时我们并不希望在这两个事件间出现这样的顺序。消息序列图注释允许通过应用一个叫做共区(coregion)的结构,从而避免对于一个处理过程而言,各个事件的某个子集出现任何特定的顺序。共区用表示处理过程的垂直线内虚线段来表示,这些虚线段内的事件是无序的。图3对图1进行了修改,它应用一个共区使事件e2和e4变得无序,它也表明了相关的优先顺序图。现在事件e2和e4是不可比较的,两者先于e5发生。
定时器结构
许多交互作用假设要用时序约束条件来限定消息流。通过应用三种专用事件:定时器设置、定时器复位和时间结束,你会很容易地在消息序列图注释中确定特定的交互作用假设。定时器设置通过将计时标记(hourglass)符号连接到一个单实体的时基上来表示;定时器复位通过将某个X连接到时基上来表示;时间结束用一根弯线将定时器的计时标记符号连接到实体时基来表示。
每一个定时器均有其特定的名字。对于每一个定时器而言,定时器复位和时间结束事件必定先于定时器设置事件。此外,时间结束事件是最后发生的事件。在图4中,在开始等待从阀和压力计实体发出消息前,控制器要启动定时器t1。控制器同时接收到来自阀和压力计的两个消息并将定时器复位,事件e7和e8表明定时器设置和定时器复位事件。图5显示了一个简明的消息序列图,图中控制器设定定时器t1(事件e7)并且在定时器t1(事件e9)时间结束前仅接受到来自阀的状态关闭(status_close)消息。
事件发生条件
条件是一种非正式描述机制,用以显示一个或一组实体达到的某个状态或情形。条件写为一个六边形框内的文本标签,可放置于某一实体或一组实体当中。如果条件C被置于实体E当中,那么除非条件得到满足,否则E不会进入到下一个事件。也就是说,条件C是实体中下一个事件发生的先决条件。如果将条件C被放置于一组实体E1,...,Ek之中,那么所有k个实体必须达到符合条件C的局部状态。只有在那个状态达到时,任何k实体才能在其相应的局部顺序中完成进一步处理。在这样的情况下,条件C可以被认为是完成进一步处理前确保实体E1,...,Ek达到相同状态的同步作用机制。
图6显示了图1中的消息序列图(稍作重新排序),并增加了一些条件,实体阀和压力计共享一个称为可用正确状态(correct_status_available)的条件。只有当这两个实体均达到满足该条件的某一状态时,它们才能按照其局部顺序进一步处理下去。该实体控制器必须达到某一状态,这个状态下实体控制器在接收状态信息前要满足准备接收状态(ready_to_receive_status)条件。这些条件的确切定义在此省略。
在线算子表达式
在线算子表达式(Inline operator expressions)是一种允许终端用户在消息序列图内确定补充控制流的机制,而且还可组合或合成多个消息序列图组。在线算子表达式当中,可以采用五种操作类型来确定控制流,分别是:
*可选择组合
*平行组合
*循环*可选区域
*例外
从图解的意义来讲,在线算子表达式用一条由虚线水平分割的矩形来描述;算子关键字(operator keyword)标准在右上角。
图7利用具有可选算子的在线表达式合并了图4和图5中的消息序列图组。矩形内的虚线分割两个交替的路径,在一次执行过程中,消息序列图仅处理其中一条路径。
补充工具
消息序列图注释为描述嵌入式系统内部的交互作用提供了更为丰富的工具。消息的收发并不限于任何特定的实体,还包括外部环境。发向外部环境的消息,箭头止于消息序列图框上;从外部环境接收消息,箭尾止于消息序列图框上。
消息可包括附加信息。例如,通过阀处理所发送的开启状态(status_open)和闭合状态(status_close),消息可以合并成单个命名状态消息,上述两个状态的消息则以“status(open)”和“status(closed)”表示,其中的变量包含了消息值。
消息序列图的动作用矩形表示,矩形内包含了将要被执行的某项任务的文字描述。与某种“条件”类似,动作矩形被置于某一实体垂直线上。然而,与某种“条件”不同的是,一个动作是局部的;它只可相连于单个实体而不可跨越多个实体。将此动作作为特殊事件加以处理,我们可将它们包括进与消息序列图相关的优先顺序图当中。与各种“条件”类似,动作通常按非正式的描述加以处理。
消息序列图组中尚存在许多其它的工具,如消息门(gates for messages)。用户也可以一种标准化的、以事件为导向的文字句法对消息序列图加以描述,而不是以这里所给出的可视注释加以描述。
高层消息序列图
基本消息序列图注释描述了微小而特殊的基本交互作用,但复杂系统又怎样处理呢?一个复杂系统通常描述为各种子系统的分级组合,其交互作用描述为子交互作用的分级组合。
高层消息序列图(HMSC)增强了基本消息序列图注释以便描述子交互作用的组合。HMSC注释也支持自上而下的分级注释,其意义在于可在不同层的提取上确定各种交互作用,即通过基础消息序列图组描述从最高层开始到最底层的交互作用。
HMSC是一组由有方向的边相互连接起来的节点集合。每一个节点既是开始符号-,也是终止符号D,圆长方形包含某一个到另一个低层或高层消息序列图的参考,六边形包含一个条件,空心圆表示一个连接点或含有两个或更多平行的高层消息序列图组(HMSCs)的平行框。就组合的方面而言,实体不在HMSC中出现。连接点仅供方便布局之用,它们没有语义。HSMC中的各种条件具有整体性,其意义在于适用于所有实体并表示某一整体系统状态。
图8所示为控制器行为的HMSC。该行为由几个通过其它HMSC和MSC来说明的低层行为组成。通过这种方式,HMSC注释就可以自顶向下分层对行为进行分解。低层的HMSC可含有更深一层的HMSC或MSC。在此要强调的是,因HMSC是循环的,所以它不含终止符。我们已强调过:一个基本MSC总是有限的;但HMSC却不是这样,因为某个HMSC可能包含多个循环(表明是周期性的或循环的行为)。
复审和确认
项目要求的复审和确认,包含在那些应用消息序列图组确定的要求,是质理管理的重要组成部分。对于已用消息序列图确定的项目要求,还可用两种方法来复审和确认,一个是运行仿真,也称之为原型或模拟,可就特殊情形测试消息序列图组;另一个是确保消息序列图组满足特定的系统特征(原理)。
后者可采用工具自动检查HMSC,你可运用与临时逻辑有关的注释来表述特性并使用诸如模型检查和满意度来验证所给特性。此外,一些专用算法和工具可用来分析给定的HMSC,以自动检测若干意外的情况,如死锁、竞争条件和非局部选择。
购买指南
消息序列图为设计实时安全和重大任务系统的工程师提供有价值的服务。类似于在UML中的序列图和应用实例注释,消息序列图组有几点优于UML的性能。例如,消息序列图简化了在早期设计阶段的概念化系统要求。消息序列图将系统及其外部与该系统相互作用的所有实体描述为一个黑盒子,图表仅包含了一个有关系统与其外部环境间交互作用的简洁而非正式的描述。黑盒子和其外部实体作为消息序列图组中的单个实体,意即你无需知道或明确有关系统的内部结构或行为,当然我们己知的交互作用除外。这样的高层黑盒子交互作用导向的系统要求在UML中就说明得不够充分。
消息序列图组也可用作测试过程的规范(综合测试)。由于你可以运用消息序列图仿真、正式验证或完善规范,你可在实时嵌入系统的生命周期内广泛运用消息序列图组。此外,消息序列图注释也正因其特殊的应用价值而在几个领域广泛运用。例如,在计时消息序列图组中,上部和下部时限可用每一个消息加以规定,使其更适用于协议和实时系统。此外,由一套消息序列图组还可制作各种文件。
作者:Girish Keshav Palshikar
Tata研究开发与设计中心
Email:
girishp@pune.tcs.co.in
Post by
carol
@
23:35
Unix Socket FAQ
-
04/04/03 22:36
Unix Socket FAQ
1 - General Information and Concepts
What's new?
About this FAQ
Who is this FAQ for?
What are Sockets?
How do Sockets Work?
Where can I get source code for the book [book title]?
Where can I get more information?
Where can I get the sample source code?
2 - Questions regarding both Clients and Servers (TCP/SOCK_STREAM)
How can I tell when a socket is closed on the other end?
What's with the second parameter in bind()?
How do I get the port number for a given service?
If bind() fails, what should I do with the socket descriptor?
How do I properly close a socket?
When should I use shutdown()?
Please explain the TIME_WAIT state.
Why does it take so long to detect that the peer died?
What are the pros/cons of select(), non-blocking I/O and SIGIO?
Why do I get EPROTO from read()?
How can I force a socket to send the data in its buffer?
Where can I get a library for programming sockets?
How come select says there is data, but read returns zero?
Whats the difference between select() and poll()?
How do I send [this] over a socket?
How do I use TCP_NODELAY?
What exactly does the Nagle algorithm do?
What is the difference between read() and recv()?
I see that send()/write() can generate SIGPIPE. Is there any advantage to handling the signal, rather than just ignoring it and checking for the EPIPE error?
After the chroot(), calls to socket() are failing. Why?
Why do I keep getting EINTR from the socket calls?
When will my application receive SIGPIPE?
What are socket exceptions? What is out-of-band data?
How can I find the full hostname (FQDN) of the system I'm running on?
How do I monitor the activity of sockets?
3 - Writing Client Applications (TCP/SOCK_STREAM)
How do I convert a string into an internet address?
How can my client work through a firewall/proxy server?
Why does connect() succeed even before my server did an accept()?
Why do I sometimes lose a server's address when using more than one server?
How can I set the timeout for the connect() system call?
Should I bind() a port number in my client program, or let the system choose one for me on the connect() call?
Why do I get "connection refused" when the server isn't running?
What does one do when one does not know how much information is comming over the socket? Is there a way to have a dynamic buffer?
How can I determine the local port number?
4 - Writing Server Applications (TCP/SOCK_STREAM)
How come I get "address already in use" from bind()?
Why don't my sockets close?
How can I make my server a daemon?
How can I listen on more than one port at a time?
What exactly does SO_REUSEADDR do?
What exactly does SO_LINGER do?
What exactly does SO_KEEPALIVE do?
How can I bind() to a port number < 1024?
How do I get my server to find out the client's address / hostname?
How should I choose a port number for my server?
What is the difference between SO_REUSEADDR and SO_REUSEPORT?
How can I write a multi-homed server?
How can I read only one character at a time?
I'm trying to exec() a program from my server, and attach my socket's IO to it, but I'm not getting all the data across. Why?
5 - Writing UDP/SOCK_DGRAM applications
When should I use UDP instead of TCP?
What is the difference between "connected" and "unconnected" sockets?
Does doing a connect() call affect the receive behaviour of the socket?
How can I read ICMP errors from "connected" UDP sockets?
How can I be sure that a UDP message is received?
How can I be sure that UDP messages are received in order?
How often should I re-transmit un-acknowleged messages?
How come only the first part of my datagram is getting through?
Why does the socket's buffer fill up sooner than expected?
6 - Advanced Socket Programming
How would I put my socket in non-blocking mode?
How can I put a timeout on connect()?
How do I complete a read if I've only read the first part of something, without again calling select()?
How to use select routine
RAW sockets
Restricting a socket to a given interface
Receiving all incoming traffic through a RAW-socket?
Multicasting
Getting IP header of a UDP message
To fork or not to fork?
Connect with timeout (or another use of select() )
7 - Sample Source Code
Looking for a good C++ socket library
perl examples of source code
Where is the source code from Richard Stevens' books?
8 - Bugs and Strange Behaviour
send() hangs up when sending to a switched off computer
Error when using inetd
Post by
carol
@
22:36
嵌入式系统 的相关学科和学习
-
04/04/03 16:43
from:
http://www.artist-embedded.org/
1 Introduction
ACM Transactions in Embedded Computing Systems - Special Issue on Education
There is now a strategic shift in emphasis for embedded systems designers:
from simply achieving feasibility, to achieving optimality
. Optimal design of embedded systems means targeting a given market segment at the lowest cost and delivery time possible. Optimality means seamless integration with the physical and electronic environment while respecting real-world constraints such as hard deadlines, reliability, availability, robustness, power consumption, and cost. In our view, optimality can only be achieved through the emergence of embedded systems as a discipline in its own right.
An important factor for the emergence of embedded systems as a discipline is the existence of integrated curricula for training engineers and researchers, able to tackle a range of topics which until now had been spread across many different areas, including:
general computer science and engineering, real-time computing, systems architecture, control and signal processing, security and privacy, networking, mathematics, electronics.
2 Curriculum Description
Guidelines for a Graduate Curriculum on Embedded Software and Systems
A.1 Basic Control and Signal Processing
Berkeley’s EECS20
URL :
http://ptolemy.eecs.berkeley.edu/eecs20/
A.2 Theory of Computing
A.2.1 Formal Language Theory (Florence Maraninchi, ENSIMAG)
URL:
http://www-ensimag.imag.fr/formations/enseignements/1e-annee/math.html#thla1
A.2.2 Syntax and Semantics (Luca Aceto, Aalborg)
URL :
http://www.cs.auc.dk/ luca/SS/ss.html
A.2.3 VERIFICATION (Kim G. Larsen, Aalborg)
URL :
http://www.cs.auc.dk/ kgl/VERIFICATION98/coursepage.html
A.3 Real-Time
A.4 Distributed Systems
A.5 System Architecture and Engineering
A.5.2 Advance Topics in Software Systems, Software Reliability Methods and Embedded Systems
(Insup Lee, University of Pensylvania
URL :
http://www.cis.upenn.edu/ lee/02cis640/
A.5.3 Real-time computer control systems (Martin Torngren, KTH)
URL :
http://www.md.kth.se/RTC/RTCC/
A.5.4 Component-Based Software Engineering (Ivica Crnkovic, Malardalen)
URL :
http://www.idt.mdh.se/kurser/cd5490/
other material:UML-RT, etc.: (http://www4.in.tum.de/~csduml02/)
Post by
carol
@
16:43
美国国家半导体推出Bluetooth1.2新品(图)
-
04/04/02 09:25
今天,美国国家半导体公司 (National Semiconductor Corporation)宣布该公司最新推出的蓝牙 (Bluetooth) 产品系列可支持最新修订的 1.2 版蓝牙技术规格。
LMX5252 芯片可支持蓝牙技术标准,是目前市场上最高度集成的射频收发器芯片。LMX5452 芯片由射频收发器与另一高性能的 1.2 版蓝牙基带处理器集成而成,并装设于小巧的微型模块封装之内。由于两款产品都采用模拟及射频高度集成的技术,只占用系统电路板很少的空间,因此可以节省系统成本,而且更可发挥更高的性能。
美国国家半导体设备连线部总监 Malcolm Humphrey 表示:「美国国家半导体的全新 LMX5452 芯片除了采用微型模块封装技术之外,也采用更高度集成的射频技术,使这蓝牙产品系列更适用于移动电话及计算系统,成为这类应用的理想解决方案。目前客户最关心的问题是解决方案的体积以及是否容易设计。
移动设备厂商只要采用美国国家半导体的微型模块解决方案,便可精简射频电路板的设计,使芯片可以更容易直接装设在主机板上,无需采用较昂贵的传统模块封装。」
蓝牙无线通信技术的优点是用户无需通过有线的连系便能利用不同的计算及通信系统交换信息,这些系统包括移动电话、电脑、打印刷、个人数字助理以至汽车。蓝牙 1.2 版的技术规格加设了多项全新的功能,其中包括更快的连线时间、改善语音传输能力及可确保蓝牙与其他 2.4GHz 设备能更好地共存的自动跳频 (AFH)。
LMX5252 芯片是一款内置 Tx/Rx 开关以及平衡和不平衡适配器的高集成度 0.18 微米 CMOS 蓝牙射频收发器,采用大小只有 6mm x 6mm x 0.8mm 的 36 管脚 LLP 封装。这款芯片可支持 10 至 40 MHz 频率范围内的多个不同系统时钟频率,Rx 灵敏度的典型值是 -84dBm。LMX5252 芯片最适用于内置蓝牙基带处理功能的处理器,例如美国国家半导体的 CP3000 系列连线处理器。
LMX5452 芯片由蓝牙收发器与基带处理器集成而成,采用大小只有 9mm x 6mm x 1.4mm 的 64 管脚微型模块 BGA 封装。基带处理器设有蓝牙 1.2 版的全部功能及固件,而且采用性能更高的主计算机接口 (HCI) 指令结构。此外,LMX5452 芯片也内置只读存储器 (ROM) 以及可与之完全互通的存储器片控制器与高度灵活的片随机存取存储器 (RAM)。
LMX5252 芯片已有样品供应,预计本月底会有大量现货供应。
Post by
carol
@
09:25
Motorola 推出Linux音乐移动电话
-
04/04/02 09:08
Motorola 推出Linux音乐移动电话
LinuxAID.com.cn站点最新信息:Motorola公司最近公布了好几种多媒体手机,其中特别有一款Motorola E680手机,采用了嵌入式Linux操作系统。据说这款手机将在美国上市,这也是该公司首次在远东地区以外推出基于Linux的手机。
E680 支持SD 存储器扩展卡,最大支持容量达到1GB。用户可以通过USB,篮牙或者GPRS等手段输入音乐、视频等内容。支持的格式包括 MP3、MPEG4、RealPlayer等。
该产品装备有240x320 象素彩色显示屏,支持电子邮件,文本,彩信以及3D游戏。在去年10月份,Motorola公司还宣布在新一代的Linux手机中增加Java功能。
多个渠道表示,E680将在美国市场上销售。这也是Motorola在中国以及亚洲其他国家推出A760手机后首次在上述地区以外销售Linux产品。
Post by
carol
@
09:08
Record - 1st, April
-
04/04/01 21:58
今天的工作,有了一点收获,用直接的rs232登陆uClinux的方法,可以替代借助irda驱动的方式,只需要在源程序上做很少的改动就可以了。
所以我今天就开始用vb写程序了。因为在打开HyperTerminal,mincom等现成的终端程序的时候,程序对某条控制的串口县进行了设置,影响到了单片机上的toim4232的设置,所以要重新写。成功以后,把这一段代码塞到原来的程序中,应该就可以通讯了。
可是,我从来没有接触过vb啊,今天胡乱弄了一天,居然把最关键的一块(波特率设置)搞定了,测试程序可以接受和发送了,但是对于数据的处理和细节设置,还不是很清楚。麻烦的是我到现在还没完全搞明白vb的语法,和c的差别大了点。嗯~~!累得了都有点晕了,明天继续。。。晕。。。
Post by
carol
@
21:58
工作日志 - 3-31
-
04/03/31 19:45
今天上午一直在看 tcp 的协议,尤其是里面几条保证传输可靠性的策略,我的通讯协议里面居然都用到了,豁豁~~ 好自豪哦
TCP
协议的可靠性:
Ø
应用数据被分割成
T C P
认为最适合发送的数据块。
If use constant baudrate (115200)
,
then ignore it.
Ø
自适应的超时及重传策略
Ø
当
T C P
收到发自
T C P
连接另一端的数据,它将发送一个确认。
Ø
首部和数据的检验和,由发端计算和存储,并由收端进行验证。――如果收到段的检验和有差错,
T C P
将丢弃这个报文段和不确认收到此报文段(希望发端超时并重发)
Ø
T C P
将对收到的数据进行重新排序
not available now
Ø
T C P
的接收端必须丢弃重复的数据
流量控制
停止等待协议
/
滑动窗口协议
agetty 和整个通过rs232登陆的过程(哑终端登陆是不是指这个),还不是明白得很透彻。关键是我对进程的理解,还太浅了,而且整个过程,好像与要我看的 pipe 没什么关系。
下午 Karl 好像顿悟了,发现一切问题都是那么的简单,只要做小小的设置改动,就可以代替原来的使用irda驱动,直接用rs232和uClinux通讯了。所以我,用要换工具了――用vb的MScomm控件,做一个类似hyterterminal的东西,不过一个field显示输出,另一个field进行输入而已。
:( 网络真差劲,发送失败,写的东西都掉了
罢了罢了,明天一天,搞定vb ~~~
Post by
carol
@
19:45
进程间通信 IPC
-
04/03/31 19:19
from
www.loveunix.net
by cheyenne
translated by carol
----------------------------------
IPC == Inter Porcess Communication
if u don t know much about TCP/IP networks and the IPC tools in UNIX, u might wonder why u need to know this information.
- RPC makes extensive use of IPC mechanisms. understanding IPC makes it easier to develop and debug RPC code. if nothing else, understanding IPC aids in ur understanding and appreciation 4 RPC and increases ur ability 2 use it.
- u ll have 2 use IPC 2 implement asynchrony, concurrency, and scheduling algorithms within RPC servers and clients. most of advanced RPC issues can only be resolved with low-level IPC programming.
- IPC mechanisms alone are enough to implement network applications. in some cases it makes more sense to develop a simple
socket-based
client/server pair than a full-blown RPC application, especially when services are available locally.
- as a tool 4 accessing remote computers, IPC allows access 2 resources similar to RPC. u can get at another host's processor or its attached peripherals. 4 example, tape drives, array processors, data acquisition units, etc. most of the network applications written before RPC were developed with low-level IPC functions. any application can make use of many powerful features of UNIX and the network using IPC.
-------------------------------------------------------------------
引用
IPC == Inter Porcess Communication
进程间通信
if u don t know much about TCP/IP networks and the IPC tools in UNIX, u might wonder why u need to know this information.
进程间通信
如果你对UNIX中TCP/IP网络和IPC(进程间通信)的工具不甚了解,那就会奇怪干吗要知道这些东西了。
说偶阿
引用
- RPC makes extensive use of IPC mechanisms. understanding IPC makes it easier to develop and debug RPC code. if nothing else, understanding IPC aids in ur understanding and appreciation 4 RPC and increases ur ability 2 use it.
RPC(Remote Procedure Call 远程过程调用) 广泛应用了 IPC 机制。理解 IPC 有助于更容易的开发和调试 RPC 代码。(转折词
),理解 IPC 可以帮助你理解 RPC, 提高你使用 RPC 的能力。
引用
- u ll have 2 use IPC 2 implement asynchrony, concurrency, and scheduling algorithms within RPC servers and clients. most of advanced RPC issues can only be resolved with low-level IPC programming.
进行远程过程调用(RPC)的服务端和客户端上实现异步,并发,和调度算法时,都会用进程间通信来实现。 大多数先进的远程过程调用(RPC)问题,只能通过底层的进程间通信编程来实现。
引用
- IPC mechanisms alone are enough to implement network applications. in some cases it makes more sense to develop a simple
socket-based
client/server pair than a full-blown RPC application, especially when services are available locally.
单独的进程间通信机制,已足够实现网络应用了。有时候,在开发一对简单的基于socket的客户/服务器时,也比整套的(full-blown)远程过程调用(RPC)更有意义,尤其当服务器是在本地的时候。
引用
- as a tool 4 accessing remote computers, IPC allows access 2 resources similar to RPC. u can get at another host's processor or its attached peripherals. 4 example, tape drives, array processors, data acquisition units, etc. most of the network applications written before RPC were developed with low-level IPC functions. any application can make use of many powerful features of UNIX and the network using IPC.
作为一种访问远程计算机的工具,进程间通信 允许访问类似 RPC 的资源。你可以获取另一个主机的进程,或者其周边设备(peripheral). 比方说, tape drives, array processors, data acquisition units 等等。大多数写于 RPC 之前的网络应用,都是用底层的进程间通信函数来写的。任何应用都可以通过进程间通信(IPC)来使用UNIX及其网络的强大特征。
转载请注明:
from
www.loveunix.net
by cheyenne
translated by carol
----------------------------------
Post by
carol
@
19:19
终端登录过程 agetty 学习
-
04/03/30 22:32
图 4-8 终端上的登录过程
agetty.c 的流程:明天补充
Post by
carol
@
22:32
�脑创��a打造一��最小化的Linux系�y��作篇
-
04/03/30 14:07
�脑创��a打造一��最小化的Linux系�y��作篇
Greg O'Keefe,
gcokeefe@postoffice.utas.edu.au
2000年09月第0.8版
以下就是�脑创��a中打造一��最小化的Linux系�y的操作�f明.它曾��是
�募与����拥�Bash提示符(From PowerUp to Bash Prompt)
的一部分.但是我�⑺���分�x�_�恚�以便使得它��更��短而更�榧�中化.我��在此所要打造的系�y是
非常
小的,而且并不准�渥��楣ぷ鳟a品�硎褂茫�如果您想�念^�_始打造一��有���H用途的系�y,���㈤�Gerard Beekmans所撰��的
Linux空手道��作指南篇 (Linux From Scratch HOWTO)
.
1.
您所需要具�涞��l件
2.
文件系�y
3.
MAKEDEV(�O�渖�成器)
4.
�群�
5.
Lilo系�y引��器
6.
Glibc��
7.
SysVinit初始化�_本包
8.
Ncurses��
9.
Bash命令解��器
10.
Util-linux (getty 和login)
11.
Sh-utils
12.
可用性商榷
13.
更多信息
13.1 �S�C小技巧
13.2 �Y源��接
14.
Administrivia
14.1 版�嗦�明(Copyright)
14.2 主��
14.3 您的反��意��
14.4 �Q�x��
14.5 修���v史����
14.6 未�碛�划(TODO)
http://www.linux.org.tw/CLDP/OLD/mini/BuildMin.html#toc10
台湾的linux工程,确实比大陆做得更系统更完善。
Post by
carol
@
14:07
tcp/ip handshaking diagram
-
04/03/29 22:46
今天看了下 tcp/ip 的通信协议,希望可以从中获取灵感,设计出比现在的通信协议更可靠,速度更快,更容易理解的新方案。汗~ 说得好象多伟大似的。
现在的协议用了两次握手来建立连接――按tcp/ip的说法,应该是四次握手。可是难道不应该一来一回算一次握手的吗?那tcp/ip就是一次半握手。:)
sender ------- init pack 1 ----------------> receiver
sender <------ Ack ------------------------- receiver
sender ------- init pack 2 ----------------> receiver
sender <------ Ack ------------------------- receiver
Post by
carol
@
22:46
Record - 29th, Mar
-
04/03/29 22:31
今天过得很平静,早上眼睛肿的,所以很困,挣不开
大多数的时间,花在了 fix bugs 上面了 ―― 这真的是一件让人觉得厌烦的事情 (awful, nightmare, ugly etc...)――以为没有问题的东西,总是会被人挑出毛病来,尤其是在老大看来很简单的一个模块,我却总能碰到些莫名其妙的问题,从开始到现在,总是这样,太打击自信心了。
更可恶的是,明明是发送端的程序问题(我想应该是的),却没有办法根除,反而要在接受端加些代码来补救,真是典型的打补丁阿 :( ―― 这让我觉得自己的思维混乱,做事情没有条理。
在串口项目的修改没有分配下来之前,蓝牙的程序还是要做――虽然也是借着虚拟串口的,但是已经让我感觉好多了,蓝牙耶!比串口听起来先进多了。@_^
上午随手翻了下以前的串口资料――其实里面好多参数设置,细节问题,我都还没有搞明白,做了大半年了,居然还不精通,说出来都惭愧啊。serial programming POSIX on unix 这篇文章是 linux 上串口编程,除 how-to 以外非常有价值的资料,搜了一下好像还没有人把它翻成中文的,我可以抽空一边学习一边写一点中文笔记,结合 《linux 程序设计》上的相关内容。上次那个翻译 linux serial programming how-to 的人,对串口的相关知识理解不深,只追求把文章翻出来,我想这样不行。how-to 的思想,就是要信息共享,翻译的过程,在保持原文思想的同时,在加入实践的经验,才有加深理解的作用。要不然大家宁愿看原文,以免被误导了。我给他改了之后,也没有回音,失望。
Post by
carol
@
22:31
下周工作计划
-
04/03/28 18:26
唉,其实是很难预期的,谁知道突然要插进来什么事情呢
Karl 明天要开会,大家讨论下关于串口通讯到底要做成什么样子。估计这是个持久战,不是一会儿可以搞定的。
Palm 蓝牙可能要暂时搁置,但我想抽点时间,可能要晚上咯,看能不能做出点结果。不管怎么说,做了好段时间了,我应该对自己负责。
Post by
carol
@
18:26
高可靠性嵌入式系统固件设计策略
-
04/03/27 14:11
设计专栏, 嵌入式系统, 设计自动化/设计复用
上网时间:2004年02月29日
本文针对如何
编写易理解、易维护的优秀代码
进行了讨论,为程序员提供了一些非常实用的编程指导。文中指出,函数功能应该最小化,代码封装便于程序维护,消除冗余能够提高程序的可靠性,适当的重构能够降低维护过程中程序熵增大的速度,提高程序的清晰度,而遵循一定的标准并采用适当的检验工具则会进一步保证代码的可靠性。
一些非正式调查显示,60%到70%的固件编写者都持有电子工程师学位,这一学历背景在帮助理解所开发的应用的物理层,以及错综复杂的硬件时,起到了很好的作用。但大多数电子工程课程都忽视了软件工程的教育。当然,教师们会教授如何编程,他们希望每个学生都能精通代码构造,但在他们所提供的教育中,缺乏对构造可靠系统所必须的软件工程关键原则的教育。
也许如今最广为人知,但却最少被采用的软件设计准则就是
保持函数短小精悍
。我曾在一次固件讲座中询问听众,多少人在编写代码时限制了函数长度,结果几乎没人举手。但事实上我们清楚,好的代码不可能很长。
如果你编写的函数超过了50行,即一页,那么这个函数已经太长。事实上,对于一个超过8或10个阿拉伯数字的字符串,我们能够记住的时间很可能无法超过1分钟。那么又怎能奢望我们能理解一个由成千上万的ASCII字符构成的函数?对于那些跨了许多页的程序而言,即使是试图跟随程序流程都很困难,甚至几乎不可能,因为我们必须不断地翻页,才能看懂那一个个嵌套着的循环是用来干什么的。
一个函数应该只实现一个功能。
如果一段代码过于缠绕不清,拼命地想完成许多不同的功能,那么这样的代码就过于复杂,不可能具备可靠和可维护的特性。我见过太多这样的函数,它们利用多达50个参数来选择成打的交互模式,这样的函数几乎都不能可靠地工作。用独立的方式表达独立的想法,将每个想法写成完全清楚的函数。经验告诉我们,当你很难找到一个能够清楚表达函数意义的名字时,说明这个函数的功能已经太多了。
封装代码
提倡面向对象编程(OOP)的人们一直在倡导“封装、继承和多态”的要求,尽管OOP并不适用于所有应用,封装却可以说放之四海而皆准。
封装的意思是将数据以及对其进行操作的代码捆绑进一个实体,这意味着任何其他代码都不能直接访问这些数据。
如果你所开发的应用中对ROM限制非常严格,每个字节都要仔细斟酌,那么这种应用基本无法封装。在几个对成本极端敏感的应用中(例如电子贺卡),将内存需求降到最低就至关重要。但是我们必须承认,这类应用的开发成本本身就非常昂贵。无论何时,只要你陷入了受字节限制的开发条件,那么开发成本就很可能高得惊人。
大家都知道,利用C++和Java编程时可以进行封装。事实上,用C和汇编开发时,同样可以进行封装。封装时要注意,所有全局变量都必须在使用到该变量的函数或模块内定义,并保证该变量不被其他程序访问。但封装并不仅仅意味着数据隐藏。一个完全封装好的对象具有很高的内聚性(cohesion),无需涉及任何与其无关的行为就能完成任务。同时,这样的对象还具备异常安全和多线程安全性。我们可以把这样的对象或函数看作一个完整的功能性黑盒子,只需很少的外部支持,或者根本无需任何支持。
一个封装得较好的序列号处理程序可能需要一个中断服务程序,用以向循环缓冲器传送它接收到的字符,需要一个get_data()程序从数据结构中提取数据,同时还需要一个is_data_available()函数,用于测试接收到的字符。它还能处理缓冲溢出、序列号缺失、奇偶错误以及所有其它可能出现的错误条件,因此,这种程序是可重入的。
对代码进行封装之后的一个必然结果就是消除了代码之间的依赖性。高内聚必然伴随着低耦合,换句话说,就是封装后的代码对其它行为的依赖性较小。我们都曾读过这样的代码,一些看起来简单的操作却与成打的其它模块纠缠不清。这时,即使只做最简单的设计修改,维护人员也不得不在成千上万行代码中跟踪变量和功能,而这肯定会把他们逼疯。
消除冗余
斯坦福大学的研究人员对160万行Linux代码进行的研究发现,即使是无害的冗余也往往和程序缺陷(bug)高度关联(参看www.stanford.edu/~engler/p401-xie.pdf)。
研究人员将
冗余定义为一段无效的代码,例如:1. 将一个变量赋给它自己;2. 初始化或设置一个变量后却从不使用它;3. 死码;4. 在复杂的条件判断语句中,一个子语句的逻辑条件已经被在其之前的子语句涵盖,因而该语句永远不会被求值。
这些研究员十分聪明,他们并未将某些特殊情况列入冗余范畴,例如用于设置一个存储映射I/O端口的代码。这类操作看起来多余,但其实是有用的。
即使那些不会造成程序缺陷的无害冗余也会引发问题,因为这些包含冗余的函数中出现硬错误的可能性比不含冗余代码的函数要高出50%。
冗余代码的出现意味着设计人员思路不清
,因此很有可能在附近出现其它错误。
此外,还要
小心成块拷贝的代码
。我个人十分赞成代码重用,也鼓励开发人员继续开发那些已经测试过的大块源代码,但是很多时候,设计人员往往在拷贝代码时,并没有对被拷贝代码的含义做足够的研究。你真的能确保,即使这段代码是来自该程序的另一部分,所有的变量也都是按你期望的方式初始化的吗?会不会有极小的
可能在程序中出现互斥,引发死锁或者竞争
?
我们拷贝代码是为了节约开发时间,但这是有代价的。我们必须比研究自己正在编写的新代码更仔细地研究这些拷贝来的代码。当lint或者编译器警告发现了未使用的变量时,必须引起注意。这可能是一个信号,意味着程序中潜伏着更多严重的错误。
减少实时代码
实时代码不但易出错、编写成本高昂,而且调试成本可能更高。如果可能,
最好将对执行时间要求严格的段落转移到一个单独的任务或者程序段中去
。如果在整个程序中处处渗透着时间问题,那么会令每一个字都变得难以调试。
如今我们所构建的系统比过去庞大得多,也复杂得多,但我们所采用的调试工具的调试能力却不如十年前的调试工具。尽管处理器的速度已经暴增至接近无穷快,在线仿真器还是我们的首选调试器,其中包括实时跟踪电路、事件定时器,甚至性能分析工具。今天,我们身边处处充斥着BDM或者JTAG调试器。这些工具用于解决程序上的问题还可以,但他们基本上没有提供任何资源用于解决时域问题。
还要请大家记住以下几个在安排开发时间表上的经验规则:一个系统负荷达到90%的系统,其开发时间是负荷小于或等于70%系统的两倍;如果系统的负荷增加到95%,那么开发时间将增大到三倍。实时应用项目的开发是十分昂贵的,高负荷的实时项目尤其如此。
编写优雅流畅的代码
这里强调的是流畅,而非跳转。要构造流畅的程序,就应该避免使用continue、goto、break或过早的return。这些语句本来都是十分有用的构造,但他们通常会降低函数的透明性。极限编程以及其它一些敏捷编程方法强调了重构(即重新编写劣质代码)的重要性。这其实并非新概念,理顺并维护编写恶劣的代码模块比维护一段结构漂亮的代码模块要昂贵得多。
重构的狂热追求者们要求我们重新编写所有那些可以被改善的代码,这就显得过于吹毛求疵。我们的工作是要用一种可盈利的方式创造能够成功的产品。追求完美这一目标不应凌驾于所有其它的考虑之上。但仍有一些函数写得太差,必须重写。
如果你害怕编辑某个函数,或者如果每次你对这个函数做一点修改,它就会出问题,那么就该重构这个函数。如果你作为一个专业开发人员,凭着你经过良好训练的直觉发现,我们最好别碰这段代码,因为没人敢与之周旋。那么就说明是时候该放下所有其它事,重写这段代码,让它变得易懂、易维护。
热力学第二定律告诉我们,任何闭合系统如果向更加无序的方向发展,其熵就会增加。程序也遵循这一令人沮丧的事实。一次又一次的维护过程常常会增加程序的无序性,使下一次的改变更加困难。正如Ron Jeffries所指出的,维护而不重构会给每次得到的软件版本增加一个“混乱因子(m)”,从而增大代码的熵。这样,每次修改软件得到的新版本的维护代价可以看做(1+m)(1+m)(1+m). . .,或者(1+m)×n,其中n是修改发布的次数。并且随着我们对程序修整和随意缩略的次数越来越多,维护代价会呈指数上升。这也是为什么有些程序员的小聪明会激怒管理者,让他们觉得“这个程序简直一团糟,没法维护”。
重构也需要付出代价,但它能消除混乱因子,使得修改发布软件的代价变成线性的1+r+r+r . .
Luke Hohmann倡导“降低老版本的熵”,他指出我们为了发布产品,常常过于频繁地做出一些快速修整,这就增大了维护成本。因此,必须还清妄自修整软件带来的技术债务。维护不仅仅是填鸭式地向软件中添加新功能,它还包含降低软件在维护过程中自然产生的熵。
同时,重构还能将含混不清的逻辑关系理顺。如果现有的代码缠绕不清、乱七八糟,那么就应重新编写它,以便更好地说明其含义。此外,还应删除那些层层嵌套的循环或条件语句。因为谁也没有那么聪明,能够明白那一层层嵌套的IF。程序越透明,就越容易正确。
遵守代码编写标准并借助检查工具
请根据你公司的固件标准来编写代码,并利用正式的代码检查工具来增强代码与标准的符合度并寻找缺陷。在检查结束之后再进行测试。用检验工具寻找缺陷比人工调试大约便宜20倍。他们能够捕捉到你通过传统测试从未检查到的各种问题。许多研究都表明,传统调试只能检查约一半代码!如果在产品发布前不使用检验工具,那么发布的很可能是一个处处隐含着缺陷的产品。
有趣的是用于构造安全性要求高的软件的DO-178B标准严重依赖于所使用的工具来保证每一行代码都被执行,这些代码覆盖工具确实是个奇迹,但它们仍然无法取代检查。
代码编写标准和检查是相辅相成的,任何一方离开另一方都不可能取得成功。而没有标准和检查就不可能构造出完美的固件。
本文小结
当我才刚刚开始我的职业生涯时,一位比我入行早的同事教了我一招:如果这该死的程序能够工作,那么就别管它。这一招他称之为基本工程原则。这是一个很有诱惑力的概念,我将其贯彻了许多年。这一原则在硬件设计中似乎还算有效,但将其用于固件设计,就将是一场灾难。我认为,“还工作得不错”就意味着项目成功的想法是部分软件危机的根源所在,然而专业人士应该明白,对一个软件发展的要求与对其功能和操作的要求同等重要。让我们共同努力,写出既漂亮又便于维护,而且能够可靠工作的程序!
参考文献:
1. Jones, Nigel. "Lint" Embedded Systems Programming, May 2002, p55
2. Berger, Arnold and Michael Barr. "On-Chip Debug" Embedded Systems Programming, March 2003, p47
3. Boehm, Barry. Software Engineering Economics. Englewood Cliffs, NJ: Prentice-Hall, 1982
4. Jones, Capers. Applied Software Measurement: Assuring Productivity and Quality. New York: McGraw-Hill, 1991
5. Jeffries, Ron. Extreme Programming Installed, Boston: Addison-Wesley, 2000
6. Ganssle, Jack. "Better, Faster Code" Embedded Systems Programming, August 1998, p117
7. Ganssle, Jack. "A Firmware Development Standard" Embedded Systems Programming, March 1998, p129
8. Ganssle, Jack. "Firmware Development Standard, Part 2" Embedded Systems Programming, April 1998, p97
Jack G. Ganssle
嵌入式开发顾问
Email: jack@ganssle.com
此文章源自《电子工程专辑》网站: http://www.eetchina.com/article_content.php3?article_id=8800330943
Post by
carol
@
14:11
市场调研揭示亚洲嵌入式系统开发趋势
-
04/03/27 14:07
设计专栏, 嵌入式系统
上网时间:2004年03月14日
Venture Development公司在2003年初预测,嵌入式操作系统、捆绑工具及相关服务的市场到2007年将超过10亿美元,其中,以亚太地区的增长最快。该公司还预测,非捆绑嵌入式软件开发工具的市场将达到5.252亿美元,年复合增长率为9.5%。
然而,Gartner公司估计,
嵌入式软件开发工具和实时操作系统(RTOS)
的市场在去年下滑了13.8%。该公司预测,市场将在2004年恢复增长,原因是电信和数据通信市场(它们是嵌入式软件工具的最大用户)正开始走出历史低谷。
无论这些预测是否准确,我们都有必要对市场做更近距离的透视。为了探寻趋势,还有什么比直接询问嵌入式系统设计师更好的方法呢?《电子工程专辑》和Gartner公司每年都向读者和网站用户进行问卷调查,以帮助他们更好地了解嵌入式系统开发的趋势。最近完成的一次市场调研旨在掌握硬件元件和开发工具的使用状况以及用户对当前工具的满意度。
该联合调查于2003年10月底进行,共收到890位嵌入式系统设计师的反馈。这些设计师主要分布在亚洲市场,包括中国大陆、韩国、台湾地区以及印度和新加坡等。
Gartner公司首席分析师Daya Nadamuni根据调查结果撰写了名为“亚洲嵌入式系统开发趋势”的调查报告。该报告显示,电信和数据通信是回复者最多的行业,占总数的27%。与2002年一样,消费电子领域位列第二,回复者占总数的比例为22%。
2003年中国大陆启动的嵌入式项目最多,新项目的加权平均值为3.74;亚洲其余地区(ROA,包括印度和新加坡)以3.72名列第二。中国大陆和台湾地区的工程师很乐观,预期2004年启动的新项目将达到4个。
报告显示,在过去一年里,64位 MPU/MCU架构和16位DSP的使用率分别增长了7.2%和10%,而16位 MPU/MCU、20、24和32位DSP的使用率均略有下降。
在其它硬件元件种类中,闪存是所有国家或地区使用率最高的器件,其中韩国以60%高居榜首。在软件方面,RTOS的使用率在不同地区分别增长了7%至66%。
Linux、VxWorks和Windows CE仍然是市场上使用最广泛的RTOS;C和汇编是最流行的固件开发语言。
该调查还显示,69%的嵌入式微元件采购决策是在架构开发和概念设计阶段做出的。相应地,RTOS的相关比例为62%;应用开发工具是58%。
基于该调查的白皮书还提供了开发工具、语言和方法学的使用状况以及用户的满意度。它还分析了采购行为并指出了影响采购决策的因素。《电子工程专辑》网站的注册用户可以下载完整的白皮书。
作者:南达
此文章源自《电子工程专辑》网站: http://www.eetchina.com/article_content.php3?article_id=8800332010
Post by
carol
@
14:07
新的blog, 新的心情, 新的开始
-
04/03/27 13:37
网络的好处,就是她是一种你可以控制的生活
随时开始,随时暂停,随时结束
可以按照自己的喜好安排生活各个方面
在这个新的blog里,我只谈谈技术,记录自己的学习过程
我想做一个优秀的工程师,虽然我是女的,但是一切并不会有所不同的
至于我的那些小女人的,或者一点都不女人味的胡言乱语,
就留在其他的blog里面
Post by
carol
@
13:37